PARSING
Pojem z oblasti ↗komputační lingvistiky, jímž se rozumí automatický (na počítači probíhající) proces přiřazování syntaktické struktury větám přirozeného jaz. zadaným na vstupu, popř. výsledek takovéhoto procesu pro jednu konkrétní větu – výslednou syntaktickou strukturu této věty (množinu výsledných struktur, pokud je jich více). Taková automatická syntaktická analýza se tak vlastně velmi podobá větnému rozboru (např. tak, jak je vyučován ve školách), rozdíl je vlastně jen ve způsobu provedení (autorem analýzy je počítač místo člověka) a velmi pravděpodobně i v detailnosti výsledků. V oblasti komputační lingvistiky existuje celé odvětví, které se zabývá metodami syntaktické analýzy – teorie p. Počítačové programy, v nichž jsou tyto metody implementovány a které syntaktickou analýzu provádějí, se nazývají ↗parsery. Podle toho, jakou syntaktickou teorií je analýza podložena, se hovoří o závislostních či složkových parserech, o GPSG-parserech, LFG‑parserech, HPSG‑parserech aj.; viz ↗formální gramatika.
Závislostní parser vytváří z věty jakožto posloupnosti slov, která jsou příp. morfologicky analyzována a disambiguována, syntaktickou strukturu obvykle v podobě ↗závislostního stromu. Složkový parser zase vytváří z věty ↗bezprostředněsložkový strom; oba typy stromů jsou zvláštními případy orientovaného grafu, který se ovšem dá vyjádřit i např. pomocí atributů a hodnot, např. v gramatice omezení (constraint grammar) aj.
V závislostním stromě každý uzel (příp. s výjimkou uzlů technických a případů lingvisticky motivovaných, jako je např. lexikálně nevyjádřená spona) reprezentuje jedno slovo, nejsou tu tedy až na výjimky žádné neterminální uzly. Některé uzly jsou spjaty závislostním vztahem (zachyceným tzv. hranou grafu). Je to vždy vztah binární mezi řídícím a závislým uzlem, přičemž hrana vede od řídícího uzlu k uzlu závislému (příp. i obráceně). Navíc bývá této hraně připsána hloubkově n. povrchově syntaktická funkce příslušného syntaktického vztahu. Např. analytická (povrchověsyntaktická) struktura věty (1) Úkol vybrat tu nejkrásnější dívku čeká na porotu. se v závislostním stromě ↗Pražského závislostního korpusu (✍The Prague Dependency Treebank 2.0, 2006) zachytí takto:
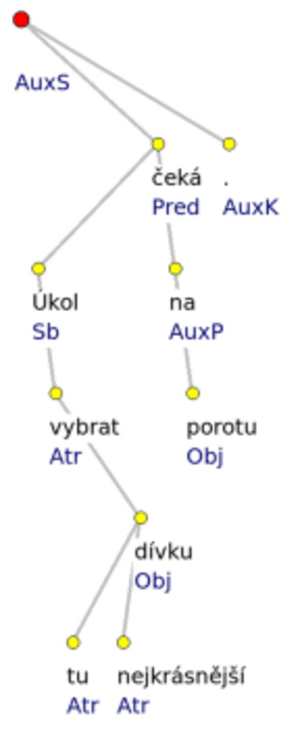
Jednotlivým uzlům stromu jsou tu přiřazeny dva údaje: slovní tvar a syntaktická funkce (Atr, AuxK, AuxP, AuxS, Obj, Pred, Sb), charakterizující závislostní vztah mezi řídícím a závislým uzlem: podřízený uzel závisí na svém řídícím uzlu typem (zde povrchověsyntaktické) závislosti připsaným závislému uzlu.
Ve složkovém stromě, kde je syntaktická struktura věty vyjádřena bezprostředněsložkovým parserem, jsou mimo terminální uzly reprezentující jednotlivá slova věty i uzly neterminální reprezentující syntaktické skupiny – fráze: např. nominální fráze, verbální fráze, klauze apod. Hrana v tomto stromě zachycuje vztah mezi složkou A a její bezprostřední složkou B, např. složka označená VP (verbální fráze) může mít své bezprostřední složky V (sloveso) a NP (nominální fráze), schematicky: [VP V NP]. Věta (1) by se ↗bezprostředněsložkovým stromem zachytila např. takto (v nejjednodušší podobě, protože strom závisí na teorii gramatiky a na analýze toho, co je v dané teorii složka; viz ↗složka):
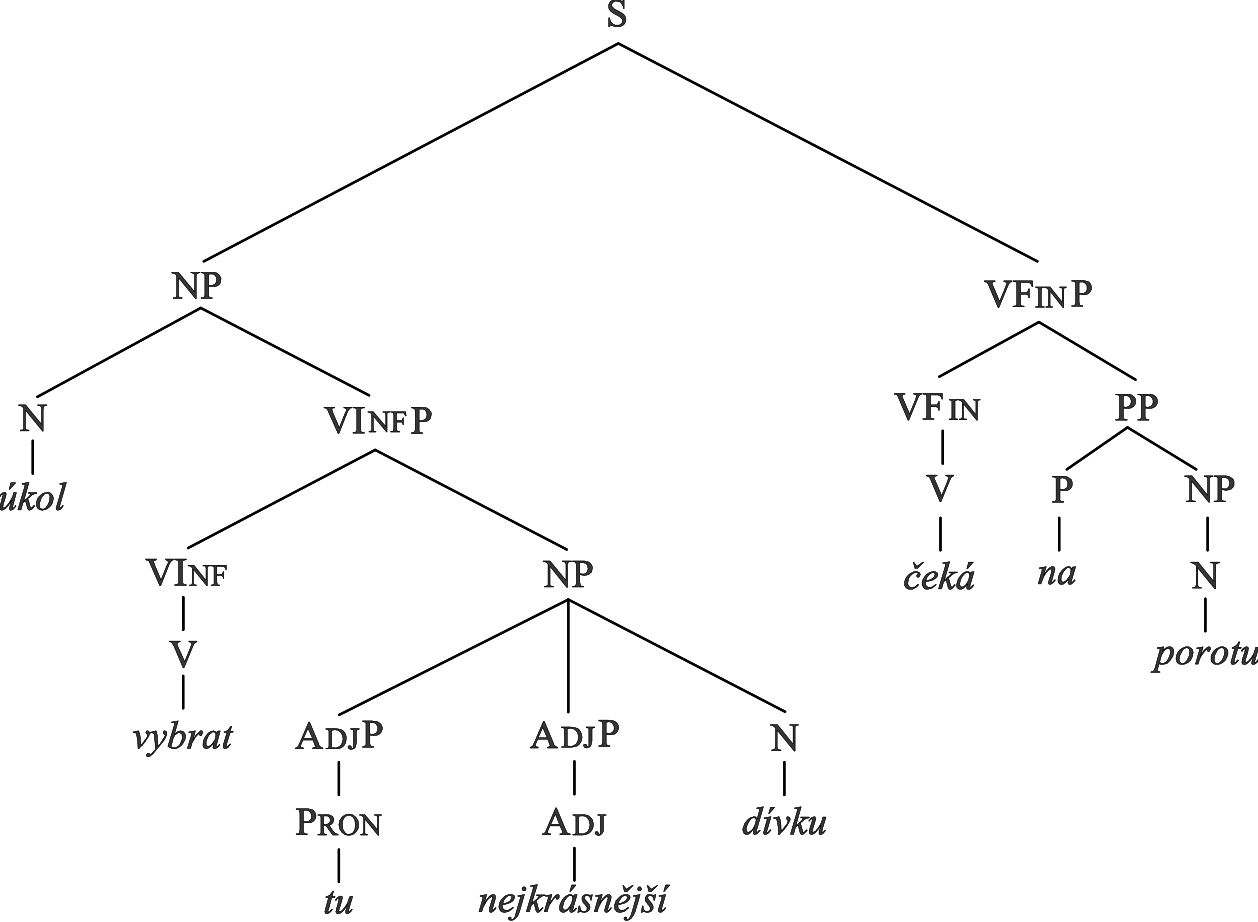
Zde Adj označuje adjektivum, AdjP – adjektivní skupina, N – substantivum, NP – jmenná skupina, P – předložka, PP – předložková skupina, Pron – zájmeno, S – věta, V – sloveso, VFin – finitní sloveso, VFinP – slovesná skupina řízená finitním slovesem, VInf – infinitiv, VInfP – slovesná skupina řízená infinitivem. Jednotlivým uzlům stromu je přiřazen buď neterminální symbol (zde syntaktická funkce n. slovní druh), n. terminální symbol (slovní tvar). ↗Bezkontextová gramatika umožňující generovat uvedený strom by obsahovala např. tato přepisovací pravidla:
S → NP VFinP |
AdjP → Adj |
AdjP → Pron |
NP → N VinfP |
NP → AdjP AdjP N |
PP → P NP |
VFinP → VFin PP |
VFin → V |
VInfP → VInf NP |
VInf → V |
Adj → nejkrásnější |
NP → N |
N → dívku |
N → porotu |
N → úkol |
P → na |
V → čeká |
V → vybrat |
P. se provádí ↗parserem (syntaktickým analyzátorem), který je buď stochastický (✍McDonald & Pereira ad., 2005; ✍Hall, 2006; ✍Nivre & Hall ad., 2006; ✍Nivre & Hall ad., 2007; ✍Nivre, 2009; ✍Nivre & Kuhlmann ad., 2009), n. je založený na pravidlech (✍Karlsson & Voutilainen ad., 1995). Pomocí p. se vytvářejí korpusy syntakticky anotovaných struktur – ↗treebanky (stromové databanky). Zvláštním případem p. je skeletonový p., což je zjednodušený p. vyvinutý ✍Leechem & Garsidem (1991). Stochastický parser je nutné „natrénovat“ na správně (manuálně) syntakticky označkovaném korpusu, jazykový model vytvořený tímto „trénováním“ lze pak použít k parsingu nového textu.
Podle postupu, jakým je výsledná syntaktická reprezentace (v naprosté většině případů syntaktický strom) vytvářena, se rozlišují parsery operující „zdola nahoru“ (bottom up) – ty vycházejí od slov věty („listů“ stromu) a až nakonec docházejí k vrcholu struktury („kořenu“ stromu), parsery operující „shora dolů“ (top down), snažící se o postup opačným směrem, a konečně existují i metody smíšené (např. left‑corner, head-corner parsers). Syntaktická analýza je pouhou součástí automatické analýzy textu a musí často spolupracovat s dalšími moduly, přinejmenším s analýzou morfologickou a velmi často i s analýzou sémantickou.
P. mimoto obecně znamená každý proces, kterým se automaticky (parserem) prověřuje strukturní správnost nějakého textu podle zadané strukturní šablony n. podle pravidel, např. prověrka struktury dokumentu v ↗XML (Extended Markup Language) podle zadané šablony zvané DTD (Document Type Definition).
Ke statutu p. v psycholingvistice viz ↗porozumění řeči.
- Hall, J. MaltParser: An Architecture for Labeled Inductive Dependency Parsing. Licentiate thesis, 2006.
- Hall, J. & J. Nivre ad. A Hybrid Constituency-Dependency Parser for Swedish. In Nivre, J. & H.-J. Kaalep ad. (eds.), Proceedings of NODALIDA-2007, 2007, 284–287.
- Hall, J. & J. Nivre. A Dependency-Driven Parser for German Dependency and Constituency Representations. In Proceedings of the ACL Workshop on Parsing German (PaGe08), 2008, 47–54.
- Charniak, E. Immediate-Head Parsing for Language Models. In Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics, 2001, 124–131.
- Karlsson, F. & A. Voutilainen ad. (eds.) Constraint Grammar. A Language-Independent System for Parsing Unrestricted Text, 1995.
- Leech, G. & R. Garside. Running a Grammar Factory: The Production of Syntactically Analyzed Corpora or ‘Treebanks’. In Johansson, S. & A.-B. Stenström (eds.), English Computer Corpora, 1991, 15–32.
- McDonald, R. & F. Pereira ad. Non-Projective Dependency Parsing using Spanning Tree Algorithms Online Learning of Approximate Dependency Parsing Algorithms. In Proceedings of HLT/EMNLP 2005, 2005, 523–530 (http://seas.upenn.edu/).
- McDonald, R. & K. Lerman ad. Multilingual Dependency Parsing with a Two-Stage Discriminative Parser, 2006a (http://seas.upenn.edu/).
- McDonald, R. & K. Lerman ad. Online Learning of Approximate Dependency Parsing Algorithms. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics: EACL, 2006b, 81–88 (http://seas.upenn.edu/).
- Nivre, J. An Efficient Algorithm for Projective Dependency Parsing. In Proceedings of the 8th International Workshop on Parsing Technologies (IWPT 03), 2003, 149–160.
- Nivre, J. Inductive Dependency Parsing, 2006.
- Nivre, J. Non-Projective Dependency Parsing in Expected Linear Time. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and 4th International Joint Conference on Natural Language Processing of the AFNLP, 2009.
- Nivre, J. & J. Hall ad. Memory-Based Dependency Parsing. In Ng, H. T. & E. Riloff (eds.), Proceedings of the Eighth Conference on Computational Natural Language Learning (CoNLL), 2004, 49–56.
- Nivre, J. & J. Hall ad. MaltParser: A Data-Driven Parser-Generator for Dependency Parsing. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC2006), 2006, 2216–2219.
- Nivre, J. & J. Hall ad. MaltParser: A Language-Independent System for Data-Driven Dependency Parsing. Natural Language Engineering 13, 2007, 95–135, 351–359.
- Nivre, J. & M. Kuhlmann ad. An Improved Oracle for Dependency Parsing with Online Reordering. In Proceedings of the 11th International Conference on Parsing Technologies (IWPT), 2009, 73–76.
- Sikkel, K. Parsing Schemata. PhD. diss., University of Twente, Enschede, 1993.
- The Prague Dependency Treebank 2.0, 2006 (http://ufal.mff.cuni.cz/pdt2.0/).
URL: https://www.czechency.org/slovnik/PARSING (poslední přístup: 28. 7. 2026)
CzechEncy – Nový encyklopedický slovník češtiny
Všechna práva vyhrazena © Masarykova univerzita, Brno 2012–2020
Provozuje Centrum zpracování přirozeného jazyka