MTT
Standardní zkratka angl. názvu lingvistické teorie Meaning ⇔ Text Theory, česky model „smysl‑text“ podle původního ruského názvu Модель «Смысл ⇔ Текст».
1 Historický přehled
Základy MTT položili v polovině 60. let 20. stol. I. A. Meľčuk a A. K. Žolkovskij. Někdy se uvádí, že MTT byla poprvé představena v jejich prvních společných publikacích (✍Žolkovskij & Meľčuk, 1965; ✍Žolkovskij & Meľčuk, 1967), ale některé z jejích hlavních myšlenek se objevily už ve starších článcích (např. ✍Žolkovskij & Leonťjeva, 1961; ✍Žolkovskij, 1964). O něco později začal s oběma zakladateli aktivně spolupracovat Ju. D. Apresjan. Na počátku 70. let, po dokončení Výkladového kombinatorického slovníku ruštiny (✍Meľčuk & Zholkovsky, 1984), začal Žolkovskij směřovat mimo vlastní MTT a Meľčuk se stal hlavním představitelem teorie. Kromě Apresjana, který se v MTT orientoval na sémantiku a lexikografii, spolupracovalo s Meľčukem a Žolkovským více než deset lingvistů (viz lit.) na popisu morfologických a syntaktických struktur různých jazyků, rozvoji metod strojového překladu nebo rozšiřování Výkladového kombinatorického slovníku ruštiny. Někteří významní ruští lingvisté, např. A. Je. Kibrik n. Je. Padučeva, se teorií MTT sice zabývali, ale jinak zůstali mimo její rámec. Vývoj MTT vyvrcholil publikací stěžejního Meľčukova díla (✍Meľčuk, 1974) s výkladem sémantické a syntaktické části teorie a prezentací oboustranné dvojité šipky ⇔ jako ochranné známky MTT. Meľčuk, který byl velmi kritický vůči sovětskému politickému systému, napsal brzy poté dopis do New York Times na podporu S. Kovaleva a A. Sacharova, vědců a obránců lidských práv. Dva měsíce po jeho zveřejnění v lednu 1976 byl Meľčuk vyhozen z Ústavu jazykovědy a v r. 1977 emigroval do Kanady, kde se na pozvání A. Clase stal profesorem na Univerzitě v Montrealu. Zde pokračoval ve vývoji MTT, sám a s několika svými studenty a kolegy z Montrealu a evropských univerzit. Patří mezi ně T. Reuther, L. Wanner, A. Polguère, S. Cahane, D. Beck, J. Milićević, B. Bohnet, A. Nasr, N. Arbatchewsky-Jumarie, S. Mantha aj. Na Univerzitě v Montrealu se Meľčukovi podařilo založit pod názvem Observatoire de linguistique Sens‑Texte malé výzkumné středisko, zaměřené převážně na MTT. Hlavním úspěchem spolupráce komunity MTT na Západě byl čtyřsvazkový Výkladový kombinatorický slovník francouzštiny (✍Meľčuk & Clas ad., 1995; ✍Meľčuk & Clas ad., 1984–1999). V Sovětském svazu a Rusku se vývoj MTT po Meľčukově odchodu v podstatě zastavil, i když řada myšlenek MTT zejména z oblasti sémantiky a lexikografie se uplatnila v Moskevské sémantické škole, neformálně vedené Apresjanem (viz ✍Boguslavsky & Iomdin, 2009). Pozoruhodnou výjimku představuje aplikace myšlenek a výsledků MTT ve velkém systému ETAP, který začali vyvíjet Apresjan a někteří jeho a Meľčukovi kolegové už od roku 1976. Od poloviny 90. let se opět navázaly vědecké kontakty mezi moskevskou a západní větví MTT (viz např. ✍Meľčuk, 1995). Od roku 2003 se každé dva roky scházejí lingvisté zaměření na MTT a jí blízká témata na konferencích. První se konala v Paříži, další pak v Moskvě (2005), Klagenfurtu (2007), Montrealu (2009), Barceloně (2011) a Praze (2013) – dvě poslední spojené s konferencí o závislostní lingvistice. MTT se zmiňuje i v kontextu jiných lingvistických teorií, viz např. ✍Weiss, 2011.
2 Hlavní postuláty
2.1 Jazyk jako zprostředkující článek mezi významem a textem
Hlavní myšlenka teorie MTT je jednoduchá: jazyk se chápe jako univerzální převodní článek významů (smyslů) do textů a naopak. Vytvořit jazykový model znamená navrhnout mechanismus, který (1) přiřadí k libovolnému danému významu (v podobě tzv. sémantické reprezentace) text (n. množinu synonymních textů) a (2) přiřadí k libovolnému danému textu význam (n. množinu významů v případě, že text je víceznačný). První přiřazení se nazývá syntéza neboli generování textu, druhé analýza textu. V 60. letech se pro model jazyka, kterým mohl být jakýkoli mechanismus s libovolnou vnitřní stavbou, používala metafora „černé skřínky“. Meľčuk trvá na tom, že v jazyce je syntéza (mluvení) primární a analýza (porozumění) sekundární. MTT je jen jednou z částí úplného modelu lidského jazykového chování (segment II následujícího vzorce, viz např. ✍Meľčuk, 2012):
Skutečnost | ⇔ | Význam | ⇔ | Texty | ⇔ | Zvuky jazyka |
I | II | III |
Vztah mezi skutečností a významem, který jí přisuzují lidé, leží mimo hranice lingvistiky. Klasická (raná meľčukovská) MTT ponechává mimo vlastní lingvistiku i oblast pragmatiky.
2.2 Roviny reprezentace
MTT se vyznačuje velmi přísným oddělením lingvistických rovin reprezentace. Nejhlubší rovina je sémantická a slouží jako aproximace významu. Mezi významem a textem jsou tři hlavní roviny: syntaktická, morfologická a fonetická (ta není podrobně zpracována). Syntaktická a morfologická rovina se dále dělí na hloubkovou (blíže k sémantice) a povrchovou. Hlubší roviny jsou univerzálnější (méně jazykově specifické) než odpovídající roviny povrchové. Při syntéze textu se sémantické reprezentaci postupně přiřazuje reprezentace hloubková syntaktická, povrchová syntaktická, hloubková morfologická, povrchová morfologická a fonetická. Při analýze textu je pořadí přiřazování obrácené. Podrobněji o sémantické, syntaktické a morfologické reprezentaci viz části 3 až 5.
3 Sémantika
Sémantická reprezentace (SemR) je síťová struktura (libovolný graf), která se skládá z uzlů zastupujících predikáty, od nichž vedou orientované ohodnocené hrany (šipky) k uzlům pro argumenty. Tyto hrany lze chápat jako sémantické závislosti, jsou však označeny jen čísly argumentů. O jeden argument se může dělit více predikátů, takže obecně SemR není stromový graf. Uzly obvykle zastupují jednotlivá slova (n. víceslovné idiomy), SemR však mohou reprezentovat lexikální významy po sémantické dekompozici. Uzly pak zastupují jednodušší slova n. elementární významy. Sémantické dekompozice lze chápat (a využívat) jako lexikografické definice. Obr. 1 níže (✍Meľčuk & Pertsov, 1987) představuje SemR odpovídající výroku (1) Pregnant women have been strongly warned by the FDA against drinking coffee, one of the small pleasures of life ‘Těhotné ženy byly důrazně varovány FDA před pitím kávy, jednou z drobných radostí života’ (případně jakémukoli synonymnímu výroku, i když má s tím původním jen málo slov společných, např. (2) ‘Úřad pro potraviny a léčiva se vší vážností upozornil nastávající matky, aby se vyhýbaly jedné z prostých radostí života: šálku kávy’). Jak vidno, uzly SemR mohou odpovídat běžným slovům dané věty: pregnant ‘těhotná’ (čtverec B1), drink ‘nápoj’ (B2) nebo coffee ‘káva’ (B3); jednotlivým tvarům slova: earlier ‘dříve’ (A3) nebo women ‘ženy’ (B1); víceslovným výrazům: pleasures of life ‘radosti života’ (C2), nebo většímu počtu elementárních slov nebo jednotek reprezentujících „kousky“ významů: intensive ‘intenzivní’ (A1), dangerous ‘nebezpečný’ (B2), results ‘má za následek’ (A2), persist ‘přetrvávat’ (A3), ‘tento řečový akt’ (A3–B3) apod. Z hlediska teorie je SemR jen jednou částí komplexnější informační struktury, kterou by měla doplnit struktura komunikační. Na obr. 1 je komunikační struktura znázorněna triviálně jako tematická (⊥) a rematická (ᴚ) oblast SemR.
Obr. 1. Sémantický graf
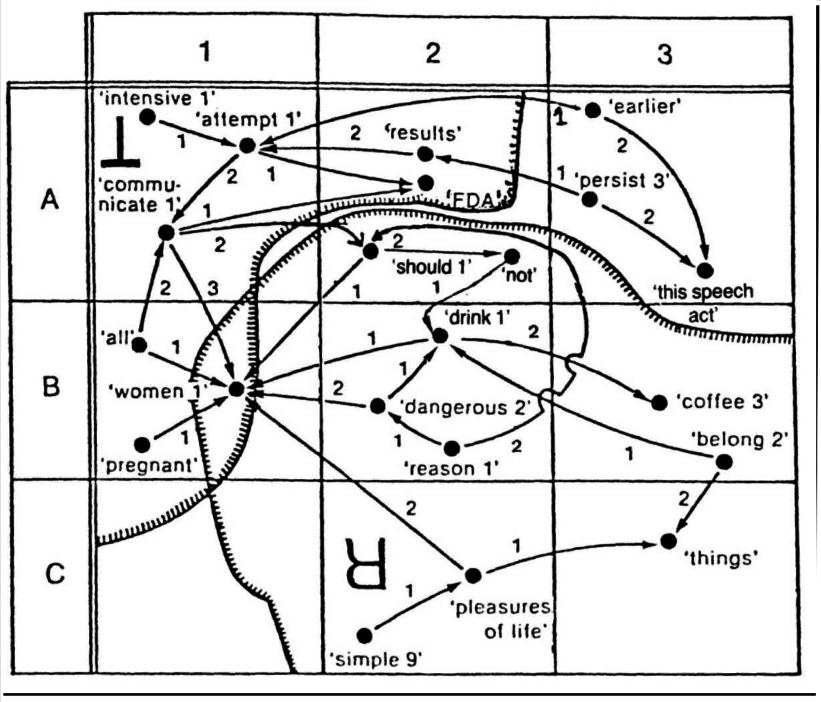
Sémantická komunikační struktura (Sem‑CommS) byla značně podrobně rozpracována v ✍Meľčukovi (2001) jako systém osmi opozic: tematičnost (réma × téma), danost (dané × staré), zaměřenost (zaměřené × nezaměřené), perspektiva (upřednostněné × upozaděné), důraz (zdůrazněné × nezdůrazněné), presupozice (předpokládané × nepředpokládané), unitárnost (unitární × rozčleněné) a výrazovost (sdělené × naznačené). Původně byla SemR v MTT považována za jedinečnou a společnou pro všechny jazyky. Žádné další podroviny se nepředpokládaly. Později zavedl ✍Apresjan (1980) jazykově specifickou rovinu povrchové sémantické reprezentace. Ukázal, že tuto rovinu si vyžaduje popis sémantických jevů charakteristických pro konkrétní jazyky, ale nepotřebných v univerzální sémantické reprezentaci. Např. sémanticky nepodstatné fragmenty významu povinně vyjadřujících pohlaví mluvčího n. posluchače v některých konstrukcích slovanských jazyků: v ruštině n. češtině nelze vyjádřit významový ekvivalent anglického I slept ‘spal/a jsem’ n. you slept ‘spal/a jsi’ bez sdělení, zda subjekt je muž n. žena. Mezi další příklady patří sémantické fragmenty vyjádřené slovanským aspektem n. pojem určitosti/neurčitosti v jazycích, které ho mají.
4 Syntax
Syntaktické struktury v MTT mají podobu ↗závislostních stromů. Formálně je závislostní strom věty orientovaný jako souvislý acyklický graf (na rozdíl od libovolného grafu sémantické struktury). Uzly stromu většinou odpovídají lexémům dané věty, přičemž orientované hrany jsou označeny názvy syntaktických vztahů. Všechny vztahy jsou binární a týkají se dvou uzlů, rodičovského a dceřiného. Jeden z uzlů stromu je jeho vrcholem (n. kořenem) a všechny ostatní uzly jsou na něm přímo n. nepřímo závislé. Předpokládá se, že závislostním stromem lze efektivně reprezentovat každou větu libovolného jazyka. Existují dva výrazně odlišné typy syntaktických závislostních stromů. Jeden typ tvoří hloubkové syntaktické struktury (DSyntS) a druhý povrchové syntaktické struktury (SSyntS). I když jsou oba typy jazykově specifické, ten první je mnohem univerzálnější. Syntaktická struktura, hloubková n. povrchová, je hlavní, ale ne jediná složka syntaktické reprezentace. Povrchová složka by měla v ideálním případě obsahovat také strukturu komunikační, anaforickou a prozodickou.
4.1 Hloubková syntaktická struktura
V DSyntS se užívá omezený počet hloubkových syntaktických vztahů. Některé z nich (1 až 7) spojují predikátové slovo s jeho argumenty (čím nižší číslo, tím vyšší pozice argumentu); jiný vztah slouží k připojení modifikátorů libovolného druhu, další představuje koordinaci, a poslední, nazývaný apenditiv (prisojediniteľnoje otnošenije), pokrývá širokou škálu volných syntaktických vztahů, vsuvky, oslovení n. citoslovce. MTT považuje tyto vztahy za jazykově nezávislé. Uzly DSyntS obvykle odpovídají lexémům, ale často představují abstraktnější entity, např. symboly lexikálních funkcí (viz níže část 6). Některé lexémy dané věty nemají v DSyntS přímý protějšek (např. vazebné předložky n. členy). Neztratí se však beze stopy, mohou být reprezentovány rysy lexikálních n. kvazilexikálních uzlů.
4.2 Povrchová syntaktická struktura
Na rozdíl od DSyntS je inventář povrchových syntaktických vztahů SSyntS specifický pro daný jazyk a také mnohem bohatší než u hloubkových syntaktických vztahů. MTT pracuje s několika desítkami takových vztahů, zpracovaných velmi podrobně pro několik jazyků, především pro angličtinu (✍Meľčuk & Pertsov, 1987), ruštinu (✍Meľčuk, 1974; ✍Iomdin & Petrov, 1975; ✍Savvina, 1976; ✍Meľčuk, 1985; ✍Uryson, 1981; ✍Iomdin, 1990; ✍Apresjan, 2010), francouzštinu (podle návrhu vytvořeného v Moskvě (✍Apresjan ad., 1983–1985) a později podstatně přepracovaného v Montrealu (✍Iordanskaja & Meľčuk, 2000)), aljutorštinu (✍Meľčuk & Savvina, 1978) aj. První podrobný popis syntaxe konkrétního jazyka podle MTT však byl vytvořen pro somálštinu (✍Žolkovskij, 1971). Meľčuk navrhl řadu kritérií, která rozlišují různé povrchové syntaktické vztahy. Důležitým kritériem je např. skutečnost, že syntaktické odlišnosti dvou konstrukcí odpovídají sémantickým rozdílům mezi nimi. Příkladem jsou konstrukce s kvantifikátory v ruštině, např. (1) pjať dnej ‘pět dní’, kde číslovka stojí před podstatným jménem, a (2) dněj pjať ‘asi pět dní’, kde je číslovka v postpozici. Slovosled, čistě syntaktický jev, je zde spojen s významem přibližnosti. SSyntS z příkladů (1) a (2) se proto reprezentují odlišnými povrchově syntaktickými vztahy: kvantitativem v (1) a aproximativem‑kvantitativem ve (2). Posledně zmíněný vztah existuje v ruštině, ale mnoho jiných jazyků, včetně č.n.angl., ho nezná. Uzly SSyntS reprezentují všechny lexikální položky odpovídající věty, včetně všech gramatických slov a lexikálních funkcí. Obr. 2 (snímek obrazovky podle analyzátoru ETAP‑3, viz bod 8 níže) ukazuje SSyntS věty (1) z bodu 3:
Obr. 2. Povrchová syntaktická struktura
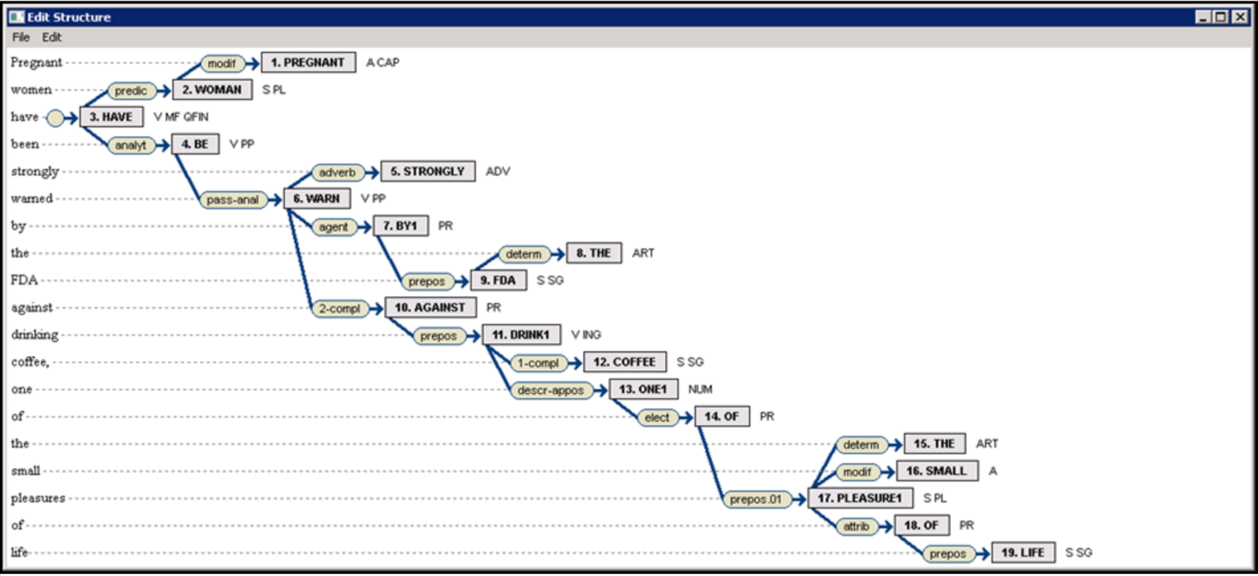
Zde je kořenem stromu pomocné sloveso have, jeho subjekt women (reprezentovaný jako lexém WOMAN s rysem PL) je závislý na tomto slovese povrchově syntaktickým vztahem predik(ativ), modifikátor pregnant závisí na women vztahem modif(ikativ) atd.
4.3 Důležité syntaktické poznatky MTT
Mezi úspěšnými výsledky syntaktických studií v MTT si zaslouží zvláštní pozornost tyto tři: (1) řešení některých nulových syntaktických členů, (2) obecné řešení diatezí, (3) rozšířený inventář a široké využití syntaktických rysů. V prvním případě Meľčuk navrhl důmyslnou interpretaci některých ruských neosobních a neurčitých osobních konstrukcí, v nichž objevil dva významově odlišné nulové subjekty, tzv. „nuľ‑ljudi“ ‘nulové lidi’ (označované jako 0люди) a „nuľ‑stichii“ ‘nulové živly’ (0стихии). První typ nulového členu se předpokládá ve větách s přísudkem v plurálu: Tropinky zasypali peskom ‘Nějací blíže neurčení lidé vysypali cestu pískem’ a druhý ve větách s přísudkem v singuláru: Tropinky zasypalo peskom ‘Nějaký přírodní jev (vítr apod.) způsobil, že cesta byla zasypána pískem’. Řešení diatezí bylo poprvé navrženo v práci ✍Meľčuka & Cholodoviče (1970), kde byla diateze definována jako korespondence mezi sémantickými a syntaktickými aktanty slovesa. Šlo o důležité zobecnění kategorie slovesného rodu. Každé sloveso má aspoň jednu diatezi, přičemž slovesný rod lze určit jen u sloves, která mají různé tvary odpovídající odlišným diatezím. Tato opozice se stala důležitou součástí ✍Meľčukova (1977) popisu složitého gramatického systému jazyka dyirbal, v němž autor navrhuje pro subjekt nový pád patetiv. Syntaktické rysy v MTT se vyznačují řadou netriviálních vlastností pro popis specifického syntaktického chování lexémů. Jedním z příkladů jsou rysy PRED, přiřazované substantivům a adjektivům, která mohou vystupovat v roli (části) přísudku, jehož gramatickým subjektem je infinitivní klauze n. vedlejší věta určitého typu. Tak třeba adjektiva wrong ‘nesprávný’ n. correct ‘správný’, opatřená rysem PREDTO, mohou stát ve větách jako it is wrong/correct to accept this proposal ‘je (ne)správné přijmout tento návrh’, zatímco adjektiva doubtful ‘nejistý’ nebo hypothetical ‘hypotetický’ s rysem PREDWHETHER umožňují věty jako it was doubtful/hypothetical whether he could accept this proposal ‘bylo nejisté/hypotetické, zda může tento návrh přijmout’. Naopak absence rysu PREDTO funkce u doubtful n. hypothetical nepřipouští věty jako *it is hypothetical to accept his proposal, absence rysu PREDWHETHER u wrong n. correct nepřipouští věty jako *it is correct whether he accepts the proposal. Rozsáhlé pojednání o přístupech MTT k syntaxi obsahuje ✍Meľčuk (1988).
5 Morfologie
MTT pracuje se dvěma podrovinami morfologické reprezentace: hloubková morfologická struktura (DMorphS) promluvy (obvykle věty), kterou tvoří uspořádaná posloupnost lemmat s kategoriemi flektivní morfologie, a povrchová morfologická struktura (SMorphS) v podobě řetězce jednotlivých morfů. Přechod mezi DMorphS a SMorphS obsahuje pravidla pro konverzi morfémů na morfy, která mohou využívat i nekonkatenativní procesy (k řešení supletivismu, alternací apod). I když přístup MTT k morfologii je poměrně tradiční, je zpracována do nejmenších detailů v ✍Meľčukovi (1993–2000), později kompletně přeloženo do ruštiny a shrnuto v ✍Meľčukovi (2006). V raném období MTT vytvořil Meľčuk, částečně jako spoluautor, pro řadu jazyků (maďarštinu, španělštinu, ruštinu, aljutorštinu a jazyk bafia) formální modely morfologie podle principů MTT; kromě ✍Meľčuka (1993–2000) viz ✍Jeskova & Meľčuk ad. (1971), ✍Meľčuk (1973); ✍Aroga Bessong & Meľčuk (1983).
6 Lexikální funkce
6.1 Pojem lexikální funkce
Pojem lexikální funkce je vizitkou teorie smysl ⇔ text. V prvních letech práce na MTT učinili Žolkovskij a Meľčuk důležitý objev. Zjistili, že mnoho typů částečně ustálených slovních spojení lze popsat podobným způsobem jako funkce v matematice. Je‑li dána funkce druhé mocniny F(x), pak můžeme vypočítat hodnotu F pro libovolný argument x. Jestliže x = 2, pak F(x) = 4 atd. Velmi podobným způsobem můžeme určit konkrétní význam, např. význam intenzifikace. Označíme‑li ho jako „Magn“ (z lat. magnus ‘velký’), můžeme pak snadno zapsat „rovnice“ jako třeba Magn(déšť) = silný, Magn(nemoc) = těžký, Magn(lež) = velký, a Magn(idiot) = naprostý. Rovnice Magn(déšť) = naprostý n. Magn(nemoc) = silný však neplatí, protože příslušné slovní spojení buď neexistuje, n. nemá význam intenzifikace. Ve výrazu Magn(déšť) = silný se déšť nazývá klíčové slovo neboli argument lexikální funkce Magn a silný její hodnota.
6.2 Typy lexikálních funkcí
Předpokládá se jazykově univerzální seznam několika desítek obecných významů (velký, malý, dobrý, špatný, pravdivý, nepravdivý, být, způsobit, likvidovat, dělat, použít apod.), které se mohou v daném jazyce vyjadřovat různě podle lexikální funkce, které v dané promluvě ve spojení s různými slovy tvoří. Následující tabulka ukazuje další dvě časté lexikální funkce, Oper1 ‘dělat’ a Oper2 ‘být předmětem něčeho’:
Klíčové slovo | Hodnota Oper1 | Hodnota Oper2 |
operace | provést | podstoupit/prodělat |
pomoc | poskytnout/zajistit | dostat/přijmout |
pozornost | věnovat/upírat/upínat | poutat/přitahovat/budit |
užitek | mít | přinášet |
Představují různé třídy kategoriálních sloves podle substantiv: Oper1 vystihuje působení prvního účastníka situace označeného klíčovým slovem (Lékař provádí operaci) a Oper2 totéž pro druhého účastníka (Pacient podstupuje operaci). Rozlišují se dvě hlavní třídy lexikálních funkcí: syntagmatická a paradigmatická. V syntagmatické lexikální funkci, jako je Magn n. Oper1/2, se argument i hodnota funkce vyskytují v textu společně. Prototypicky tvoří kolokace (velké překvapení, přednést přednášku). Argument a hodnota lexikální funkce se však mohou objevit daleko od sebe, a to i v jiných větách: Překvapení nemohlo být tak velké; Vyslechl jsem jen první přednášku. Přednesl ji slavný lingvista profesor Sgall. Paradigmatické lexikální funkce popisují synonymii, antonymii, konverzi a derivaci různého typu. Například lexikální funkce S0 se používá k popisu typických deverbativních substantiv typu nomina actionis, S1 – nomina agentis a S2 – nomina patientis:
Klíčové slovo | Hodnota S0 | Hodnota S1 | Hodnota S2 |
zkoušet | zkouška | zkoušející/examinátor | zkoušený/kandidát |
prodávat | prodej | prodávající | zboží |
získat | získání/akvizice (proces) | nabyvatel | akvizice (objekt) |
léčit | léčba/léčení/terapie | lékař | nemocný/pacient |
Argumenty a hodnoty paradigmatických n. substitučních lexikálních funkcí se obvykle nevyskytují v textu společně, ale objevují se v různých textech, které vyjadřují stejný význam. Synonymní texty by mohly být vytvořeny pomocí lexikálních funkcí a pravidel pro parafráze, např. X ⇔ Oper1(S0(X)) S0(X), např. krást ⇔ spáchat krádež (zde X je krást, S0(krást) = krádež, a Oper1(krádež) = spáchat). Lexikální funkce mají dvě důležité vlastnosti: jsou idiomatické v rámci daného jazyka (daná lexikální funkce má různé hodnoty pro různé argumenty) i napříč jazyky (hodnoty dané lexikální funkce pro argumenty, které jsou v různých jazycích překladovými ekvivalenty, nemusí být navzájem přímými překlady mezi sebou; např. angl. bitter enemy, dosl. ‘hořký nepřítel’, kde bitter je Magn(enemy), ale nikoli rus. *gorkij vrag, kde gorkij je běžný překlad bitter; n. rus. kruglyj durak, angl. utter fool ‘úplný blázen’, ale nikoli *round fool, kde round je běžný překlad kruglyj ‘kulatý’. Posledně zmíněná vlastnost předurčuje lexikální funkci k využití v oblasti lidského i automatického překladu. Podrobná pojednání o lexikálních funkcích a jejich využití v lingvistické teorii a aplikacích poskytují ✍Wanner (ed.) (1996), ✍Apresjan (2007). Důležitý příspěvek k teorii přinesl ✍Apresjan (2008) a ✍Apresjan (2011), který ukázal, že hodnoty lexikálních funkcí, a to i u zdánlivě sémanticky prázdných typů jako Oper, jsou ve skutečnosti sémanticky motivované.
7 Lexikografie
7.1 Hlavní pojmy
Lexikografie je jednou z nejrozvinutějších částí MTT. Ústředním lexikografickým pojmem je lexém, tedy slovo v jednom konkrétním významu. Proti lexému stojí pojem vokabule, tj. heslo výkladového slovníku obsahující všechny významy daného slova. Každý lexém daného jazyka je ve slovníku uveden jako samostatné heslo. (Termín vokabule je Meľčukovou reinterpretací rus. vokabula a představuje množinu lexémů s identickými formami a základními významovými prvky, přičemž všechny lexémy dané vokabule mají mezi sebou vztah polysémie.)
7.2 Výkladový kombinatorický slovník
V MTT byl vyvinut nový druh slovníku, tzv. výkladový kombinatorický slovník // Explanatory Combinatorial Dictionary (ECD), ve kterém jsou všechny lexémy (včetně frazémů, tj. idiomů a nekompozicionálních víceslovných výrazů) popsány konzistentním a podrobným způsobem. Slovníkové heslo je v ECD rozděleno do několika zón, z nichž nejdůležitější jsou: (1) sémantická zóna, kde jsou uvedeny slovníkové definice; (2) syntaktická zóna, která ukazuje rekční schéma klíčového slova včetně možností, jak naplnit jeho sémantické valence, (3) kombinatorická zóna, ve které jsou uvedeny hodnoty všech lexikálních funkcí pro dané klíčové slovo. Slovníkové definice se běžně uvádějí v textové podobě s proměnnými, které odkazují na základní složky významu slova, především na jeho aktanty. Definice jsou formulovány tak, aby nevznikl bludný kruh (např. když je slovo A vysvětleno pomocí slova B, jehož definice odkazuje zpět na A), což v ideálním případě znamená, že si definice vystačí jen se slovy, jejichž význam je jednodušší než význam definovaného slova. Další zóny ECD obsahují údaje morfologické, konotace, pragmatické a encyklopedické informace a rozsáhlou zónu příkladů. Uvádíme slovníkovou definici slovesa лечить ‘léčit’ v jeho hlavním významu z prvního ruského ECD (✍Meľčuk & Zholkovsky, 1984):
ЛЕЧИ́ТЬ 1a. X лечит Y(‑a) от W‑a Z‑ом = X воздействует на существо Y или его орган Y средством или процедурой Z с целью прекратить W – болезнь или травму Y‑a – или с целью прекратить следствия W‑а (‘X léčí Y(‑a) na W(‑u) Z(‑em)’ = X působí na bytost Y nebo orgán Y prostředkem nebo procedurou Z, aby se zamezilo W – nemoci nebo úrazu/zranění Y‑a, nebo aby se zastavily následky W – překlad je přibližný). |
Vzhledem k enormní pracnosti vytvoření kompletního ECD pro jeden jazyk jsou zatím hotové jen malé části: první ruský ECD má asi 280 hesel a čtyřdílný francouzský ECD (✍Meľčuk & Clas ad., 1984–1999) má jen 510 hesel. Ke kompilaci obou slovníků bylo třeba více než deset let.
7.3 Vliv lexikografie MTT
Přes skromný rozsah publikovaných ECD je vliv lexikografických prací MTT obrovský. Utvářely přístupy použité v některých inovativních lexikálních databázích, např. DICO (✍Steinlin & Kahane ad., 2005; ✍Meľčuk & Polguère, 2006; ✍Polguère, 2006); v teorii a praxi parafrázování (✍Apresjan & Cinman, 2002; ✍Milićević(ová), 2007); v řadě nových slovníků nového typu, vytvořených v rámci Moskevské sémantické školy, jako jsou např. ✍Apresjan & Apresjan ad. (2004) a ✍Apresjan & Apresjan ad. (2010), ale i elektronické kombinatorické slovníky, určené pro širokou škálu aplikací (viz níže). Hlavní teoretické výsledky dosažené na základě lexikografických a sémantických přístupů MTT zahrnují podrobné rozpracování predikátových slov (✍Boguslavskij, 1996), vývoj teorie rekce (✍Apresjan, 2007; ✍Apresjan, 2010) a rozšíření pojmu valence (viz např. ✍Boguslavsky, 2003; ✍Boguslavskij & Iomdin, 2011).
8 Aplikace
MTT a její součásti byly implementovány ve velkých systémech skupinou výzkumníků, původně vedenou Apresjanem. V současné době tato skupina pracuje v Laboratoři komputační lingvistiky v Ústavu problematiky přenosu informací A. A. Charkeviče Ruské akademie věd. Nejdůležitějšími aplikacemi jsou: (1) systém strojového překladu ETAP, založený na pravidlech, který překládá zejména mezi ruštinou a angličtinou, a to oběma směry (viz např. ✍Apresjan ad., 1992); (2) první syntakticky anotovaný textový korpus v Rusku SynTagRus (✍Boguslavsky & Chardin ad., 2002; ✍Boguslavsky & Iomdin ad., 2011a; ✍Boguslavsky & Nivre ad., 2008); (3) systém synonymního parafrázování promluv (✍Apresjan & Cinman, 2002; ✍Apresjan & Boguslavsky ad., 2009); (4) nástroj pro učení jazyka s pomocí počítače, který pomáhá při zvládnutí slovní zásoby a slovních spojení v ruštině, angličtině a němčině, z velké části založený na lexikálních funkcích (✍Apresjan & Ďačenko ad., 2008); (5) hloubkový sémantický analyzátor využívající ontologii (✍Boguslavsky & Iomdin ad., 2010; ✍Boguslavsky, 2011). Prakticky všechny aplikace jsou volitelnými součástmi víceúčelového jazykového procesoru ETAP‑3, který využívá sdílené zdroje inspirované MTT, včetně syntaktických analyzátorů ruštiny a angličtiny. Analyzátory vycházejí z povrchových pravidel syntaktické analýzy a kombinatorických slovníků (CD) ruštiny a angličtiny, které jsou vytvořeny podle vzoru ECD (avšak bez slovníkových definic, které v CD chybí). Oba slovníky mají asi 100 000 hesel, z nichž téměř 10 000 má zónu lexikálních funkcí. Korpus SynTagRus, který nyní obsahuje asi 900 000 slov, je anotován závislostními stromy s Meľčukovými povrchově syntaktickými vztahy a obsahuje informace o lexikálních funkcích argumentů a hodnot.
9 Vliv teorie MTT na bohemistiku
MTT se některými svými východisky (lingvistické prostředí vzniku obou teorií, časová shoda vzniku, důraz na formální gramatiku, inspirace strojovým překladem, sémantická orientace, stratifikace jazykových rovin) blíží teorii ↗FGP. Autoři spojení s FGP od 60. let citují autory z okruhu MTT (✍Panevová, 1967; ✍Panevová, 1971), srovnání obou teorií viz ✍Žabokrtský (2005). MTT také ovlivnila pojetí diateze a konverze ve FGP (✍Panevová & Marková, 2000; ✍Kováčová, 2005; ✍Kettnerová, 2015). Mimo FGP byly teorií MTT inspirovány např. práce o kategoriálních slovesech (✍Herrmannová‑Dreselová, 1987) a o českých rezultativních vazbách (✍Giger, 2003).
- Apresjan, Ju. D. Tipy informacii dlja poverchnostno-semantičeskogo komponenta modeli „Smysl ⇔ Text“. WSA, Sonderband 1, 1980.
- Apresjan, Ju. D. Trechurovnevaja teorija upravlenija: leksikografičeskij aspekt. In Achapkina, Ja. E. & A. V. Bondarko ad. (eds.), Tipologija jazyka i teorija grammatiki, 2007, 17–21.
- Apresjan, Ju. D. O semantičeskoj motivirovanosti leksičeskich funkcij-kollokatov. VJa, 2008, 3–33.
- Apresjan, Ju. D. Semantičeskije osnovy glagoľnogo upravlenija: leksikografičeskij aspekt. In Problemy grammatiki i tipologii, 2010, 27–36.
- Apresjan, Ju. D. K novoj versii teorii leksičeskich funkcij (LF). In Meždunarodnaja konferencija, posvjaščennaja 50-letiju Peterburskoj tipologičeskoj školy, 2011, 21–26.
- Apresjan, Ju. D. ad. Lingvističeskoje obespečenije sistemy francuzsko-russkogo avtomatičeskogo 1perevoda ETAP-1, 1983–1985.
- Apresjan, Ju. D. ad. ETAP-2: The Linguistics of a Machine Translation System. META 37, 1992, 97–112.
- Apresjan, V. Ju. & Ju. D. Apresjan ad. Novyj objasniteľnyj slovar sinonimov russkogo jazyka, 2004.
- Apresjan, V. Ju. & Ju. D. Apresjan ad. Prospekt Aktivnogo slovarja russkogo jazyka, 2010.
- Apresjan, Ju. D. & I. M. Boguslavskij ad. Lingvističeskoje obespečenije v sisteme ETAP-2, 1989.
- Apresjan, Ju. D. & I. M. Boguslavskij ad. Lingvističeskij processor dlja složnych informacionnych sistem, 1992.
- Apresjan, Ju. D. & I. M. Boguslavsky ad. Lexical Functions in NLP: Possible Uses. In Klenner, M. & H. Visser (eds.), Computational Linguistics for the New Millenium: Divergence or Synergy?, 2002, 55–72.
- Apresjan, J. & I. Boguslavsky ad. ETAP-3 Linguistic Processor: A Full-Fledged NLP Implementation of the MTT. In First International Conference on Meaning-Text Theory (MTT‚ 2003), 2003, 279–288.
- Apresjan, Ju. D. & I. M. Boguslavsky ad. Lexical Functions in Actual NLP-Applications. In Wanner, L. (ed.), Selected Lexical and Grammatical Issues in the Meaning–Text Theory, 2007, 199–230.
- Apresjan, Ju. D. & I. M. Boguslavsky ad. Semantic Paraphrasing for Information Retrieval and Extraction. In Andreasen, T. ad. (eds.), Flexible Query Answering Systems. 8th International Conference „FQAS 2009”, 2009, 512–523.
- Apresjan, Ju. D. & I. M. Boguslavskij ad. Teoretičeskije problemy russkogo sintaksisa: Vzaimodejstvije grammatiki i slovarja, 2010.
- Apresjan, Ju. D. & L. L. Cinman. Formaľnaja modeľ perifrazirovanija predloženij dlja sistem pererabotki tekstov na jestestvennych jazykach. Russkij jazyk v naučnom osveščenii 2, 2002, 102–146.
- Apresjan, Ju. D. & P. V. Ďačenko ad. O kompjuternom učebnike leksiki russkogo jazyka. Russkij jazyk v naučnom osveščenii 14, 2008, 48–112.
- Aroga Bessong, D. P. & I. A. Meľčuk. Un modèle formel de la conjugaison bafi (à l’indicatif). Bulletin of the School of Orieintal and African Studies 46, 1983, 477–528.
- Boguslavskij, I. M. Sfera dejstvija leksičeskich jedinic, 1996.
- Boguslavsky, I. On the Passive and Discontinuous Valency Slots. In First International Conference on Meaning-Text Theory, 2003, 16–18.
- Boguslavsky, I. Semantic Analysis Based on Linguistic and Ontological Resources. In Proceedings of the 5th International Conference on Meaning-Text Theory (МТТ‚ 2011), 2011, 25–36.
- Boguslavsky, I. & V. Dikonov ad. Semantic Representation for NL Understanding. In Kompjuternaja lingvistika i intellektuaľnyje technologii, 2013, 124–136.
- Boguslavsky, I. & I. Chardin ad. Development of a Dependency Treebank for Russian and its Possible Applications in NLP. In González Rodríguez, M. & Suárez Araujo, C. P. (eds.), Proceedings of the Third International Conference on Language Resources and Evaluation (LREC-2002) 3, 2002, 852–856.
- Boguslavskij, I. M. & L. L. Iomdin. Moscow Semantic School. In Kempgen, S. & P. Kosta ad. (eds.), Die slavischen Sprachen – The Slavic Languages 1, 2009, 813–827.
- Boguslavsky, I. & L. Iomdin ad. Interfacing the Lexicon and the Ontology in a Semantic Analyzer. In COLING 2010. Proceedings of the 6th Workshop on Ontologies and Lexical Resources (Ontolex 2010), 2010, 67–76.
- Boguslavskij, I. M. & L. L. Iomdin. Valentnyje svojstva avtoderivatov. In Boguslavskij, I. M. & L. L. Iomdin (eds.), Slovo i jazyk, 2011, 79–94.
- Boguslavsky, I. & L. Iomdin ad. Rule-Based Dependency Parser Refined by Empirical and Corpus Statistics. In Proceedings of the International Conference on Dependency Linguistics (Depling‚ 2011), 2011a, 318–327.
- Boguslavsky, I. & J. Nivre ad. Parsing the SYNTAGRUS Treebank of Russian. In Coling 2008. Proceedings of the Conference 2, 2008, 641–648.
- Jeskova, N. A. & I. A. Meľčuk ad. Formaľnyj modeľ russkoj morfologii, 1. Formoobrazovanije susčesviteľnych i prilagateľnych, 1971.
- Giger, M. Resultativa im modernen Tschechischen: unter Berücksichtung der Sprachgeschichte und der übrigen slavischen Sprachen, 2003.
- Herrmann-Dresel, E. Funktionsverbgefüge im Russischen und Tschechischen, 1987.
- Iomdin, L. L. Avtomatičeskaja obrabotka teksta na jestestvennom jazyke: modeľ soglasovanija, 1990.
- Iomdin, L. L. & I. A. Meľčuk ad. Fragment modeli russkogo poverchnostonogo sintaksisa, 1. Predikativnyje sintagmy. Naučno-techničeskaja informacija, serija 2, 7, 1975, 30–43.
- Iomdin, L. & V. Petrochenkov ad. ETAP Parser: State of the Art. In Computational Linguistics and Intellectual Technologies. International Conference (Dialog‚ 2012), 2012, 830–843.
- Iomdin, L. L. & N. V. Petrov. Fragment modeli russkogo poverchnostonogo sintaksisa, 2. Kompletivnyje i prisvjazočnyje konstrukcii. Naučno-techničeskaja informacija, serija 2, 11, 1975, 22–32.
- Iordanskaja, L. & I. Meľčuk. The Notion of Surface-Syntactic Relation Revisited (Valence-Controlled Surface-Syntactic Relations in French). In Iomdin, L. L. & L. P. Krysin ad. (eds.), Slovo v texte i v slovare, 2000, 391–433.
- Kettnerová, V. Lexikálně sémantické konverze ve valenčním slovníku, 2015.
- Kováčová, K. Konverzívnost jako systémový vztah, 2005.
- Meľčuk, I. A. Modeľ sprjaženija v aljutorskom jazyke 1, 2, 1973.
- Meľčuk, I. A. Opyt teorii lingvističeskich modelej «Smysl ⇔ Text», 1974.
- Meľčuk, I. A. The Predicative Construction in the Dyirbal Language: Towards the Notions ‘Grammatical Subject’, ‘Transitivity’, ‘Accusative Case’, ‘Ergative Construction’, and ‘Grammatical Voice’, 1977.
- Meľčuk, I. A. Meaning-Text Models: A Recent Trend in Soviet Linguistics. Annual Review of Anthropology 10, 1981, 27–62.
- Meľčuk, I. A. Poverchnostnoj sintaksis russkich čisslovych vyraženij. WSA, Sonderband 16, 1985.
- Meľčuk, I. A. Dependency Syntax: Theory and Practice, 1988.
- Meľčuk, I. A. Russkij jazyk v modeli «Smysl ⇔ Text», 1995.
- Meľčuk, I. A. Cours de morphologie générale 1–5, 1993–2000.
- Meľčuk, I. A. Communicative Organization in Natural Language. The Semantic-Communicative Structure of Sentences, 2001.
- Meľčuk, I. Aspects of the Theory of Morphology (ed. D. Beck), 2006.
- Meľčuk, I. A. Semantics. From Meaning to Text, 2012.
- Meľčuk, I. A. & A. Clas ad. Dictionnaire explicatif et combinatoire du français contemporain 1–4, 1984–1999.
- Meľčuk, I. A. & A. Clas ad. Introduction à la lexicologie explicative et combinatoire, 1995.
- Meľčuk, I. A. & A. A. Cholodovič. K teorii grammatičeskogo zaloga. Narody Asii i Afriki 4, 1970, 111–124.
- Meľčuk, I. A. & N. V. Pertsov. Surface Syntax of English: A Formal Model within the Meaning-Text Framework, 1987.
- Meľčuk, I. & A. Polguère. Dérivations sémantiques et collocations dans le DiCo/LAF. In Blumenthal, P. & F. J. Hausmann (eds.), Langue française, Special Issue on Collocations „Collocations, corpus, dictionnaires”, 2006, 66–83.
- Meľčuk, I. A. & Je. N. Savvina. Toward a Formal Model of Alutor Surface Syntax: Nominative and Ergative Constructions, 1978.
- Meľčuk, I. A. & A. K. Zholkovsky. Explanatory Combinatorial Dictionary of Modern Russian: Semantico-Syntactic Studies of Russian Vocabulary. WSA, 1984.
- Milićević, J. La paraphrase. Modélisation de la paraphrase langagière, 2007.
- Panevová, J. Strojový překlad v SSSR. SaS 28, 1967, 287–290.
- Panevová, J. Nové svazky sborníku Mašinnyj perevod i prikladnaja lingvistika, vyp. 11, Moskva, 1969, vyp. 12, Moskva, 1969. SaS 32, 1971, 69–72.
- Panevová, J. & K. Marková. Opisanije dvuch tipov konversivnych par. In Iomdin, L. L. & L. P. Krysin ad. (eds.), Slovo v texte i slovare, 2000, 202–211.
- Polguère, A. Structural Properties of Lexical Systems: Monolingual and Multilingual Perspectives. In Proceedings of the Workshop on Multilingual Language Resources and Interoperability (COLING/ACL 2006), 2006, 50–59.
- Sannikov, V. Z. Russkije sočiniteľnyje konstrukcii. Semantika. Pragmatika. Sintaksis, 1989.
- Savvina, Je. N. Fragment modeli russkogo poverchnostonogo sintaksisa, 3. Sravniteľnyje konstrukcii (sravniteľnyje i otsojuznyje sintagmy). Naučno-techničeskaja informacija, serija 2, 1, 1976, 38–43.
- Steinlin, J. & S. Kahane ad. Compiling a „Classical” Explanatory Combinatorial Lexicographic Description into a Relational Database. In Proceedings of the Second International Conference on the Meaning Text Theory, 2005, 477–485.
- Uryson, Je. V. Poverchnostno-sintaktičeskoje predstavlenije russkich appozitivnych konstrukcij. WSA 7, 1981, 155–215.
- Wanner, L. (ed.) Lexical Functions in Lexicography and Natural Language Processing, 1996.
- Wanner, L. (ed.) Recent Trends in Meaning-Text Theory, 1997.
- Weiss, D. MTT Meets Construction Grammar: The Treatment of Argument Structure. In Boguslavsky, I. & L. Wanner (eds.), Proceedings of the 5th International Conference on Meaning-Text Theory, 2011, 294–304.
- Žabokrtský, Z. Resemblances between Meaning ⇔ Text Theory and Functional Generative Description. In Apresjan, Ju. D. & L. L. Iomdin (eds.), East-West Encounter: Second International Conference on Meaning ⇔ Text Theory, 2005, 549–557.
- Žolkovskij, А. K. O pravilach semantičeskogo analyza. Mašinnyj perevod i prikladnaja lingvistika 8, 1964, 17–32.
- Žolkovskij, А. K. Sintaksis somali. Glubinnyje i poverchnostnyje struktury, 1971.
- Žolkovskij, А. K. & N. N. Leonťjeva ad. O principiaľnom ispoľzovanii smysla při mašinnom perevode. Trudy Instituta točnoj mechaniki i vyčisliteľnoj techniki AN SSSR, 2: Mašinnyj perevod, 1961, 17–46.
- Žolkovskij, А. K. & I. A. Meľčuk. O vozmožnom metode i instrumentach semantičeskogo syntéza. Naučno-techničeskaja informacija 5, 1965, 23–28.
- Žolkovskij, А. K. & I. A. Meľčuk. O semantičeskom sinteze. Problemy kibernetiki 19, 1967, 177–238.
URL: https://www.czechency.org/slovnik/MTT (poslední přístup: 27. 7. 2026)
CzechEncy – Nový encyklopedický slovník češtiny
Všechna práva vyhrazena © Masarykova univerzita, Brno 2012–2020
Provozuje Centrum zpracování přirozeného jazyka