SLOVNÍ BOHATSTVÍ TEXTU
Různě chápaný koncept měření míry koncentrovanosti textu vzhledem k použitému lexiku, tedy vztah počtu různých slov (typů) ke všem slovům (↗tokenům) v textu. Též bohatství slovníku či rozsah lexika (vocabulary richness // lexical richness). Existuje mnoho různých způsobů výpočtu s.b.t., zpravidla se však jedná o různé modifikace základního indexu označovaného jako type-token poměr (type-token ratio // TTR). Ten vyjadřuje poměr počtu různých slov, tzv. typů (V), k počtu všech slov vyskytujících se v textu, tzv. tokenů (N); viz ↗type-token:
|
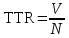
Koncept měření s.b.t. tvoří tradiční oblast kvantitativní lingvistiky, poprvé se jím patrně zabýval britský statistik (✍Yule, 1944), jenž použil s.b.t. k charakterizaci literárních děl. Právě klasifikace textů z hlediska stylu je ústřední aplikací s.b.t. v lingvistice a literární vědě. V č. lingvistickém prostředí se s.b.t. soustavně věnovala především M. Těšitelová (viz např. ✍Těšitelová, 1972; ✍Těšitelová, 1974; ✍Těšitelová, 1987).
Zásadním problémem při používání TTR jako indexu vyjadřujícího s.b.t. je jeho závislost na délce textu. Tato závislost je způsobena tím, že slovní zásoba je omezená, tudíž je nemožné, aby s rostoucí délkou textu mohl úměrně také narůstat počet nových lexikálních jednotek. Krátké texty proto mají z principu vyšší TTR než dlouhé texty. Tento fakt znemožňuje relevantně porovnávat různě dlouhé texty, což vylučuje použití TTR z většiny stylometrických analýz. Proto bylo učiněno mnoho pokusů o eliminaci vlivu délky textu na měření s.b.t.
TTR v 760 českých textech |
|
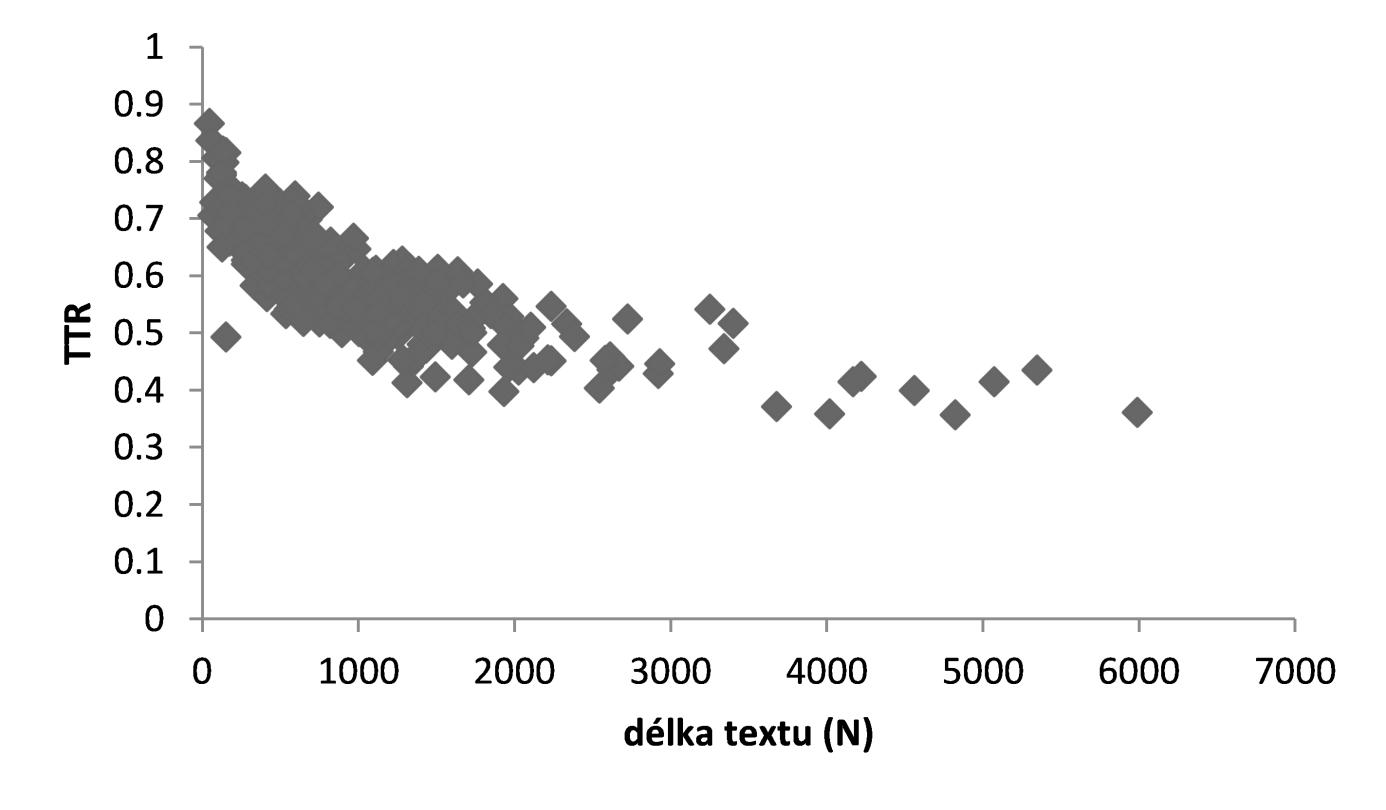
Odstranění nežádoucího vlivu délky textu na měření s.b.t. lze dosáhnout (a) modifikací vzorce pro výpočet s.b.t. takovým způsobem, aby vliv délky textu byl buď částečně, n. zcela eliminován, (b) zásahem do textu, a to jeho mechanickým zkrácením (např. na prvních 100 tokenů), na které je aplikován TTR. Ad (a) Vzhledem k tomu, že dosud nebyl navržen jediný index, který by byl zcela nezávislý na délce textu, zdá se, že jeho nalezení je zřejmě z principu nemožné, neboť při použití proměnných V a N se vliv délky alespoň do určité míry musí projevit. Ad (b) Zkrácení analyzovaných textů na stejnou délku je sice řešením, které vliv délky textu eliminuje, ale z lingvistického hlediska se jedná o postup velmi diskutabilní. Dochází totiž k porušení homogenity textu, přičemž měření provedená mechanicky na vydělených částech můžou vést k neadekvátním interpretacím: autor např. záměrně použije jiný slovník v úvodu a jiný v závěru, vyjmutí jedné pasáže textu tak může být značně zavádějící. Jednou z možností, jak tento nedostatek překonat, je segmentace textu na n subtextů, ve kterých se měří TTR a následně je vypočítán aritmetický průměr výsledků jednotlivých měření, tzv. standardizovaný type-token poměr (standardised type-token ratio // STTR) (✍Scott, 2013). Výhodou této metody oproti zkrácení textu na určitou délku je možnost analýzy celého textu. Problém STTR ale spočívá v tom, že hranice mezi jednotlivými měřenými úseky – tzv. okny (windows) – je zcela umělá a neodpovídá přirozeným celkům uvnitř textu. Proto byl navržen průběžný průměrný type-token poměr (moving average type-token ratio // MATTR) (✍Covington & McFall, 2010), který je založen na STTR, liší se však v tom, že jednotlivá okna se vždy posouvají o 1 token, tudíž se vzájemně překrývají a pokrývají celý text bez mechanicky stanovených hranic. Vzorec pro výpočet je následující:
|
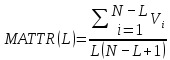 ,
,kde N je délka textu, L je (arbitrárně zvolená) délka okna a Vi je počet typů v okně.
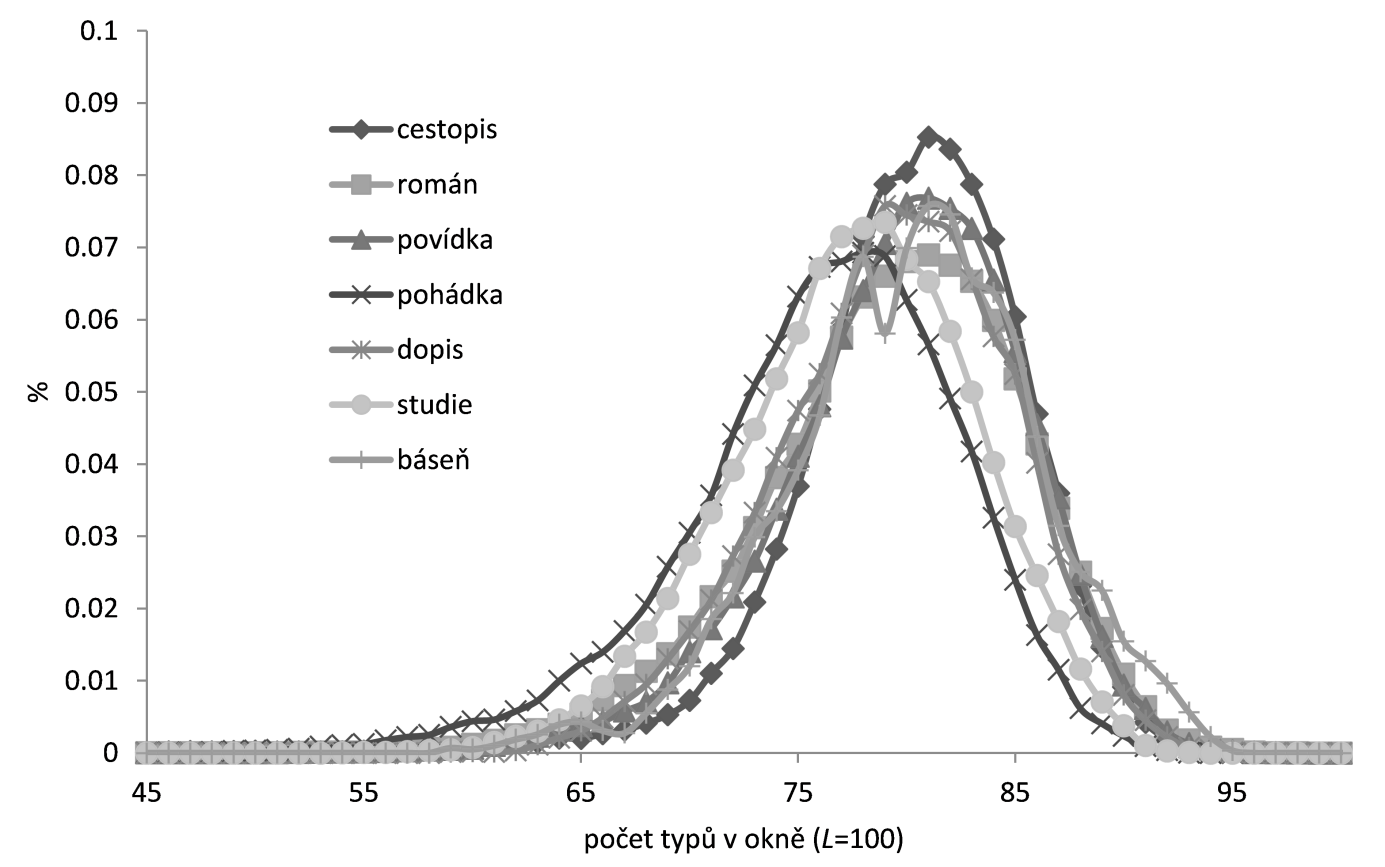
Výsledkem MATTR je pouze jedna číselná hodnota vyjadřující s.b.t., což je do jisté míry zjednodušující postup. Proto byla navržena přesnější metoda měření distribuce průběžného průměrného type-token poměru (moving window type-token ratio distribution // MWTTRD) (✍Kubát & Milička, 2013). MWTTRD se tak od MATTR liší pouze tím, že výsledkem je celá distribuce, a ne pouze jedna hodnota (průměr). Ačkoliv je MWTTRD přesnější než MATTR, analýzy ukazují, že pro diferenciaci textů či stylů není mezi těmito metodami velký rozdíl, navíc lingvistická interpretace a statistické vyhodnocení výsledků jsou v případě MWTTRD složitější (srov. ✍Kubát & Milička, 2013). Následující obrázek ukazuje výsledky MWTTRD analýzy na textech různých žánrů, přičemž na ose x je počet typů v okně o velikosti 100 tokenů (L=100) a na ose y je potom jejich procentuální zastoupení.
MWTTRD v různých žánrech |
|
Vedle metod založených na TTR existují i další metody, které bezprostředně souvisejí s bohatstvím slovníku, nejčastěji jde o index opakování slov (repeat rate), ↗entropii, Giniho koeficient, indikátor R1, poměr ↗hapax legomenon k délce textu atd. Všechny tyto metody jsou založeny na analýze frekvenční distribuce slov v textu, ale i u těchto se projevuje vliv délky textu (srov. ✍Kubát a kol., 2014).
Slovní bohatství však není problematické jen z hlediska nalezení vhodné metody pro měření, ale také z hlediska interpretace celého konceptu. Někteří lingvisté totiž odmítají, že TTR a z něj odvozené metody reflektují s.b.t. Výsledky těchto měření interpretují jako míru informačního toku (information flow) (srov. ✍Wimmer, 2005:361–368; ✍Popescu a kol., 2009:233–234). Vycházejí z předpokladu, že každý podavatel textu si je vědom, jak přibližně dlouhý text bude produkovat. Této délce potom přizpůsobí koncentraci lexika, přičemž se očekává, že čím je delší text, tím nižší je slovní bohatství a naopak. Jinými slovy, u krátkých textů je vzhledem k nedostatku prostoru produktor nucen více koncentrovat lexikum, zatímco u dlouhých textů je lexikum více rozptýlené, aby rovnoměrně pokrylo celý text. Dále se předpokládá, že každý člověk vědomě na základě pragmatických faktorů, zvláště s ohledem na adresáta, určuje míru slovního bohatství, např. nízkou koncentraci lexika mají pohádky určené dětem a vysokou naopak odborné texty určené nadprůměrně vzdělaným lidem.
Dalším problematickým aspektem měření s.b.t. je výběr základní jednotky. Zpravidla se pracuje se slovními tvary či ↗lemmaty. Při interpretaci výsledků měření s.b.t. je třeba nejen adekvátně zohlednit volbu jednotky, ale v případě lemmat také explicitně uvést způsob ↗lemmatizace.
- Altmann, G. & G. Wimmer. Review Article: On Vocabulary Richness. Journal of Quantitative Linguistics 6, 1999, 1–9.
- Covington, M. A. & J. D. McFall. Cutting the Gordian Knot: The Moving-Average Type-Token Ratio (MATTR). Journal of Quantitative Linguistics 17, 2010, 94–100.
- Köhler, R. & M. Galle. Dynamic Aspects of Text Characteristics. In Hřebíček, L. & G. Altmann (eds.), Quantitative Text Analysis, 1993, 46–53.
- Kubát, M. & J. Milička. Vocabulary Richness Measure in Genres. Journal of Quantitative Linguistics 20, 2013, 339–349.
- Kubát, M. & V. Matlach ad. QUITA – Quantitative Index Text Analyzer, 2014.
- Popescu, I.‑I. & J. Mačutek ad. Aspects of Word Frequencies, 2009.
- Popescu, I.‑I. & M. N. Vidya ad. Word Frequency Studies, 2009.
- Scott, M. WordSmith Tools, 2013.
- Těšitelová, M. On the So-called Vocabulary Richness. Prague Studies in Mathematical Linguistics 3, 1972, 103–120.
- Těšitelová, M. Otázky lexikální statistiky, 1974.
- Těšitelová, M. Kvantitativní lingvistika, 1987.
- Wimmer, G. The Type-Token Relation. In Köhler, R. & G. Altmann ad. (eds.), Quantitative Linguistics. An International Handbook, 2005, 361–368.
- Yule, G. U. The Statistical Study of Literary Vocabulary, 1944.
URL: https://www.czechency.org/slovnik/SLOVNÍ BOHATSTVÍ TEXTU (poslední přístup: 31. 7. 2026)
CzechEncy – Nový encyklopedický slovník češtiny
Všechna práva vyhrazena © Masarykova univerzita, Brno 2012–2020
Provozuje Centrum zpracování přirozeného jazyka