SHLUKOVÁ ANALÝZA
Jedna z vícerozměrných statistických metod, pomocí nichž je možné klasifikovat objekty na základě jejich podobnosti či příbuznosti. Shluková analýza je buď nehierarchická, n. hierarchická. Výsledkem nehierarchické s.a. je zařazení objektů do předem zvoleného počtu skupin (shluků) tak, aby objekty, které jsou si „podobné“, byly zařazeny do stejné skupiny, a objekty, které jsou si „málo podobné“, byly zařazeny do různých skupin. Způsob určování podobnosti je možné volit různě. Výsledkem hierarchické s.a. je tzv. dendrogram, který znázorňuje objekty uspořádané ve stromové struktuře. Rozmístění objektů v dendrogramu zohledňuje vzájemnou „příbuznost“, resp. „nepříbuznost“ objektů.
Existuje několik metod s.a.; srov. ✍Izenman (2008). U všech je prvním krokem u každého objektu určit soubor znaků, který se vyjádří ve formě vektoru číselných charakteristik. Pokud tyto soubory znaků nelze stanovit, je možné v případě některých metod použít matici vyjadřující nepodobnost objektů, tj. jde o matici, v níž prvek ij obsahuje informaci o nepodobnosti mezi objektem i a objektem j.
Mezi nejznámější nehierarchické metody patří: (1) k-means, (2) k-medoids a (3) metody založené na hustotě normálního rozdělení.
(1) Metoda k-means rozděluje n objektů do k shluků tak, aby se minimalizovala funkce, která vyjadřuje celkový součet „nepodobností“ v rámci jednotlivých shluků. Tato funkce vyjadřuje celkový součet vzdáleností mezi jednotlivými objekty shluku a tzv. centroidem shluku, který je definován jako centrální prvek shluku ve smyslu aritmetického průměru (reprezentuje tedy „těžiště“ shluku), konkrétně
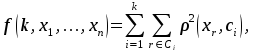
kde ρ je euklidovská vzdálenost vektorů znaků, Ci je množina indexů těch objektů x, které patří do i-tého shluku a ci je tzv. centroid i-tého shluku. Minimalizace této funkce představuje náročný problém diskrétní optimalizace, na jehož řešení se používají různé heuristické algoritmy. Tyto algoritmy jsou standardně implementovány do statistických softwarů, srov. např. volně dostupný The R Project for Statistical Computing (https://r-project.org/).
(2) Metoda k-medoids je založena na podobném principu jako metoda k-means (tj. rozděluje n objektů do k shluků tak, aby se minimalizovala funkce, která vyjadřuje celkový součet „nepodobností“ v rámci jednotlivých shluků) s tím rozdílem, že funkce vyjadřuje celkový součet vzdáleností mezi jednotlivými objekty shluku a tzv. medoidem shluku, který je definován jako centrální prvek shluku ve smyslu mediánu; konkrétně
kde d je míra „nepodobnosti“ (např. euklidovská či manhattanská vzdálenost vektorů znaků atd.) a mi je index objektu, který se nazývá medoidem i-tého shluku a je určený tím, že minimalizuje  . Stejně jako u metody k-means představuje minimalizace této funkce náročný problém diskrétní optimalizace, na jehož řešení se používají různé heuristické algoritmy. Výhodou této metody (oproti k-means) je jednak její nižší citlivost na vliv odlehlých pozorování (srov. obecně vztah mezi průměrem a mediánem), jednak to, že prostřednictvím medoidu lze identifikovat konkrétní objekt shluku, který je možné interpretovat jako typického reprezentanta tohoto shluku.
. Stejně jako u metody k-means představuje minimalizace této funkce náročný problém diskrétní optimalizace, na jehož řešení se používají různé heuristické algoritmy. Výhodou této metody (oproti k-means) je jednak její nižší citlivost na vliv odlehlých pozorování (srov. obecně vztah mezi průměrem a mediánem), jednak to, že prostřednictvím medoidu lze identifikovat konkrétní objekt shluku, který je možné interpretovat jako typického reprezentanta tohoto shluku.
Na obr. 1 je výsledek nehierarchické s.a. prostřednictvím metody k-medoids, u níž byly vektory znaků stanoveny na základě frekvence grafémů ve vybraném ruském textu (RUS) a paralelním překladu do deseti jiných slovanských jaz. (BUL – bulharština, CRO – chorvatština, CZE – čeština, MAC – makedonština, SLO – slovinština, SVK – slovenština, SRB – srbština, POL – polština, UKR – ukrajinština a UPS – hornolužická srbština); medoidmi jsou zde: SRB pro shluk v levé horní části, UKR pro shluk vpravo, SVK a CZE pro dolní shluk, což je dáno tím, že tento shluk je tvořen pouze dvěma objekty (data a jejich charakteristiky jsou převzaty z ✍Koščové & Mačutka ad., 2015).
Obrázek 1. Výsledek nehierarchické s.a. pomocí metody k-medoids
(3) V případě metod založených na hustotě normálního rozdělení se shluky vytvářejí aplikací metody maximální věrohodnosti (✍Anděl, 2007). Výhodou těchto metod je to, že dokážou odhalit také shluky nesférického tvaru (tj. shluky, které nemají tvar kruhu či elipsy), překrývající se shluky atp. Tyto metody lze ale aplikovat pouze v případě, že vektory znaků pocházejí z normálního rozdělení – lingvistická data však v naprosté většině případů normální rozdělení nevykazují, proto je případné použití těchto metod v lingvistice omezené.
Pro všechny metody nehierarchické s.a. je možné vypočítat tzv. siluety, jejichž prostřednictvím se dá určit, jak dobře jsou jednotlivé objekty zařazeny do shluků. Siluety tedy vyjadřují míru centrálnosti objektu v rámci daného shluku. Silueta s pro r-tý objekt je dána vztahem
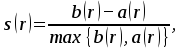
kde a(r) vyjadřuje průměrnou nepodobnost r-tého objektu vzhledem k ostatním objektům shluku, ve kterém se vyskytuje, a b(r) vyjadřuje průměrnou nepodobnost r-tého objektu s objekty jiného (nejbližšího) shluku. Pokud se s(r) blíží hodnotě 1, je r-tý objekt dobře zařazen do shluku, pokud je hodnota s(r) blízká 0, r-tý objekt se nachází na okraji shluku, záporná hodnota s(r) naznačuje, že r-tý objekt nemusí být vhodně zařazen do daného shluku. Na obr. 2 jsou znázorněny siluety pro shluky z obrázku 1: je zřejmé, že objekt SLO má siluetu blízkou 0, což se na obrázku 1 projevuje
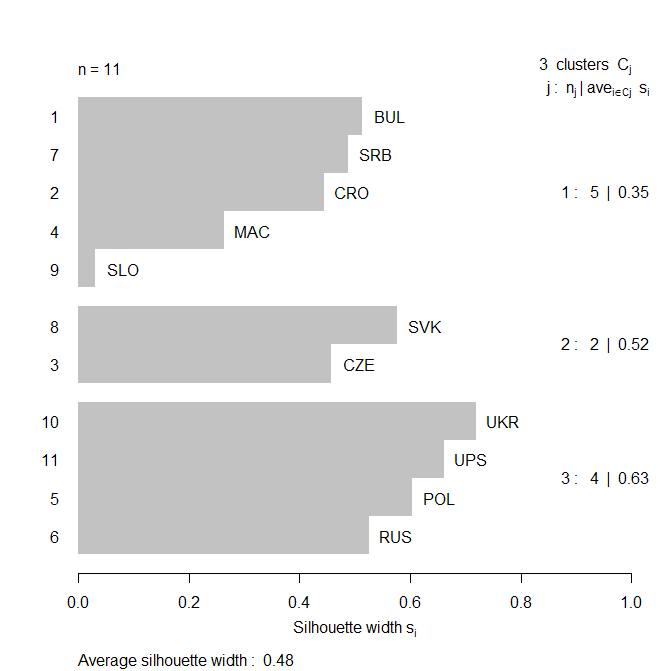
Obrázek 2. Siluety pro shlukování z Obrázku 1
tím, že tento objekt je docela „blízko“ shluku, který tvoří objekty POL, RUS, UKR, UPS. Počet shluků k je většinou určen na základě potřeb konkrétní interpretace dané analýzy. Pokud ale není dopředu znám očekávaný počet shluků, je možné optimální počet odhadnout například na základě tzv. loketního diagramu (obr. 3), který pro jednotlivé k znázorňuje minimální hodnotu funkce f (k, x1, … xn) v případě k-means, resp. g (k, x1, … xn) v případě k-medoids. Optimálním počtem shluků je takové k, při kterém je zaznamenán poslední výraznější pokles funkce celkové nepodobnosti – graficky vyjádřeno jde o nejostřejší zlom křivky, ve tvaru lokte. Jiný způsob určování vhodného počtu shluků je uveden v ✍Seberovi (2004) a ✍Rencherovi (2002).
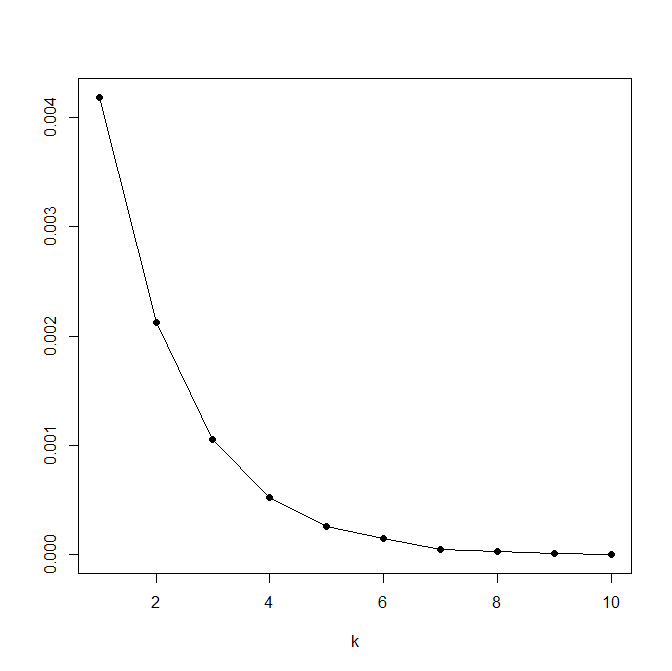
Obrázek 3. Loketní diagram – vhodná volba počtu shluků je 3, 4, případně 5
Hierarchická s.a. nabízí možnost sledovat strukturu shlukování, a to prostřednictvím stromové struktury, tzv. dendrogramu. Způsob tvorby dendrogramu je závislý na použité metodě: jedná se buď o (i) aglomerativní shlukování, n. (ii) divizivní shlukování.
(i) Při aglomerativním shlukování se dendrogram vytváří směrem zdola nahoru. Na začátku analýzy je n shluků, přičemž v každém shluku je jeden objekt. Následně se určí dva nejbližší shluky a sloučí se do nového shluku. Tímto způsobem se postupuje, dokud nejsou všechny objekty ve společném shluku. Při vytváření dendrogramu je důležité pořadí, v jakém se shluky slučovaly, a také jejich vzdálenosti před sloučením.
(ii) Při divizivním shlukování se dendrogram vytváří směrem shora dolů. Na začátku analýzy jsou všechny objekty v jednom společném shluku. Nejnepodobnější objekt se vyčlení do nového shluku společně s dalšími objekty, které jsou nejnepodobnějšímu objektu blíže než ostatním objektům, tj. všechny objekty se rozdělí do dvou shluků. V každém nově vzniklém shluku se tento postup opakuje, dokud nejsou všechny objekty v samostatných shlucích. Stejně jako v případě aglomerativního shlukování je důležité pořadí, v jakém shluky vznikaly.
Vzdálenost mezi dvěma shluky u hierarchické s.a. je možné měřit několika způsoby:
(a) metoda nejbližšího souseda (nearest neighbour, simple linkage):
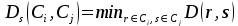 ;
;
(b) metoda nejvzdálenějšího souseda (farthest neighbour, complete linkage):
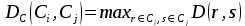 ;
;
(c) průměrná vzdálenost (angl. average linkage), která je definovaná jako průměr vzdáleností všech možných dvojic objektů (prvním z dvojice je prvek shluku Ci a druhý z dvojice je prvek shluku Cj)
(d) Wardova vzdálenost
kde ρ je (euklidovská) vzdálenost a ci, cj a cij jsou centroidy. První suma vyjadřuje součet vzdáleností objektů od jejich společného centroidu v případě, kdy jsou dva porovnávané shluky sloučeny do shluku jednoho; výraz v závorce je daný součtem vzdáleností objektů od jejich centroidů v případě, kdy dva porovnávané shluky zůstanou oddělené.
Další metody měření vzdálenosti mezi dvěma shluky uvádí ✍Seber (2004) a ✍Rencher (2002).
Na obr. 4 je znázorněn dendrogram reprezentující výsledek aglomerativní hierarchické s.a., kterou prezentují ✍Divjak & Gries (2006). Jedná se o s.a. devíti významově podobných ruských slov (synonyma slovesa „pokoušet se“). Vodorovné čáry spojující dvojice shluků znázorňují jejich vzájemnou vzdálenost před sloučením do shluku, tj. objekty (v tomto případě slova), které byly sloučeny dříve, jsou si více příbuzné než objekty, které byly sloučeny později.
Obrázek 4. Výsledek hierarchické s.a. ve formě dendrogramu
- Anděl, J. Základy matematické statistiky, 2007.
- Divjak, D. & S. T. Gries. Ways of Trying in Russian: Clustering Behavioral Profiles. Corpus Linguistics and Linguistic Theory 2, 2006, 23–60.
- Izenman, A. J. Modern Multivariate Statistical Techniques, 2008.
- Koščová, M. & J. Mačutek ad. A Data-based Classification of Slavic Languages: Indices of Qualitative Variation Applied to Grapheme Frequencies. Journal of Quantitative Linguistics, 2016 (v tisku).
- Moisl, H. Cluster Analysis for Corpus Linguistics, 2015.
- Rencher, A. C. Methods of Multivariate Analysis (Second Edition), 2002.
- Seber, G. A. F. Multivariate Observations, 2004.
URL: https://www.czechency.org/slovnik/SHLUKOVÁ ANALÝZA (poslední přístup: 25. 4. 2024)
Další pojmy:
kvantitativní lingvistikaCzechEncy – Nový encyklopedický slovník češtiny
Všechna práva vyhrazena © Masarykova univerzita, Brno 2012–2020
Provozuje Centrum zpracování přirozeného jazyka