NANOSYNTAX
Jedna z teorií v rámci generativní gramatiky; viz např. Nordlyd, 36.1, 2009 (http://septentrio.uit.no/). Staví na závěrech a výsledcích jiných generativních teorií jako ↗G&B, ↗MP, ↗DM a jiných. Duchovním otcem n. je M. Starke a mnoho výsledků a publikací je spojených s jeho působištěm CASTL v Tromsø. V poslední době se n. uplatňuje šířeji také na univerzitě v Gentu a jinde. Na rozdíl od takřka všech předchozích teorií je n. založena na tom, že syntax spojuje dohromady pouze jednotlivé gramatické rysy, a nikoliv lexikální jednotky (předsyntaktické trsy rysů v DM, páry zvuk‑význam v jiných teoriích). Pokud je lexikon tím, v čem především tkví jedinečnost konkrétního jaz., pak platí, že n. je v určitém smyslu teorií syntaxe bez (konkrétního) jaz. ✍Starke (2009) tak tvrdí, že „jednotky charakteristické pro jednotlivé jazyky jako morfémy nebo slova nejsou v syntaxi přítomny. Syntax je abstraktní rekurzivní procedura, která spojuje formální rysy jako ‚počitatelnost‘, ‚singularita‘, ‚určitost‘, ‚děj‘, ‚minulost‘ atp., aniž by se tato procedura zabývala tím, jakým slovům nebo morfémům tyto jednotky odpovídají“. V tom, že základní stavební jednotkou struktury jsou jednotlivé rysy, je n. podobná tzv. lingvistické kartografii (viz mj. ✍Cinque, 1999), ale liší se od ní právě svým přístupem k lexikálním jednotkám. Zatímco v n. mohou lexikální jednotky odpovídat celé komplexní struktuře s mnoha rysy, v kartografických přístupech jsou lexikální jednotky terminálními uzly. Kartografie a n. však sdílí myšlenku, že každý terminální uzel odpovídá právě jednomu rysu, viz také ✍Kayne, (2005).
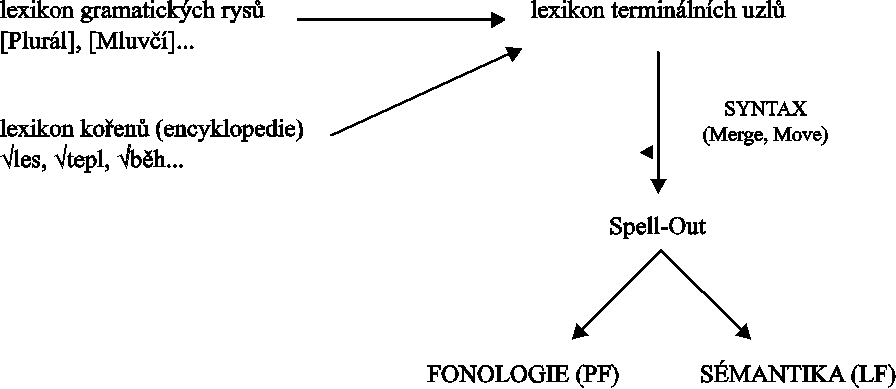
N. je stejně jako ↗DM teorií, kde jsou lexikální jednotky vkládány do struktury po syntaxi. Srov. model gramatiky těchto dvou teorií; DM v (1) a n. ve (2).
(1) Model jazyka v DM:
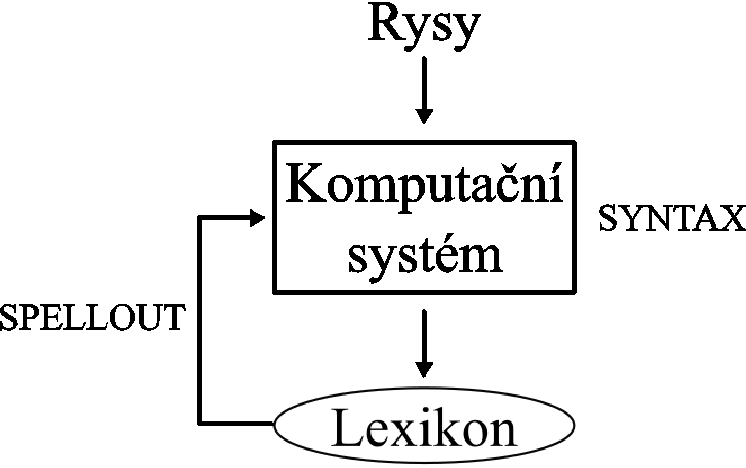
V nanosyntaxi naopak platí, že „syntax je zcela prelexikální a lexikon je pouze mechanismem externalizace syntaxe“, což odpovídá modelu (2):
(2) Model jazyka v nanosyntaxi:
Pokud jsou rysy základními stavebními jednotkami, jak tvrdí n., a pokud morfémy mohou vyjadřovat několik rysů současně, pak to znamená, že každý takový morfém musí být vyjádřením několika terminálních uzlů. ✍Starke (2009) proto tvrdí, že morfémy odpovídají neterminálním komplexním uzlům. V důsledku se lexikální jednotky stávají uspořádanou trojicí, kde na jedné straně stojí komplexní syntaktický uzel a na straně druhé fonologická a konceptuální informace. Lexikální jednotky tedy obecně mají následující podobu:
(3) | Lexikální jednotky |
< fonologie, syntaktický strom, konceptuální význam > | |
např. anglický minulý čas ‑ed: | |
< [id / d /t], [minulost [ pasivum [ výsledek [ stav ]]]], MINULOST > |
Spell out je pak pochopen jako operace, která porovnává tvar syntaktického stromu se syntaktickými stromy uloženými v lexikonu, a pokud dojde ke shodě (match), spell out převede syntaktický strom na fonologii asociovanou v lexikální jednotce s daným stromem.
V okamžiku, kdy lexikální jednotky přestanou být pouhými terminálními uzly, mohou odpovídat syntaktickým frázím různých velikostí. Tyto různé stromy přiřazené lexikálním jednotkám vedou k různému chování těchto jednotek, které pak mohou být řazeny k různým kategoriím. Jedna možná hypotéza je pak to, že např. verbální jména mají víc struktury než obyčejná jména; n. že slovesa (bělet) mají víc struktury než adjektiva (bílý), jak např. tvrdí ✍Baker (2003). N. tedy umožňuje nový zajímavý přístup k ↗lexikálním kategoriím (jedna může obsahovat druhou) a liší se tak od klasických teorií, jako např. rychle zastarávající teorie ✍Chomského (1970), která je založena na ekvipolentních opozicích rysů.
Teorie n. dále nabízí nový pohled na synkretismus (✍Starke, 2002). „Pokud povolíme, aby shoda mezi syntaktickou strukturou a strukturou uloženou v lexikonu nebyla úplná (tj. strom uložený v lexikonu se nemusí beze zbytku shodovat se syntaktickou strukturou), ale pouze částečná, pak každá lexikální jednotka může odpovídat celé řadě syntaktických struktur, jejichž omezený repertoár poskytne teoretické zakotvení pro restrikce na synkretismus“ (✍Starke, 2009:3).
Tato částečná shoda mezi syntaxí a lexikonem je zakotvena pomocí tzv. principu nadmnožiny (superset principle). Jedná se o princip, který vyjadřuje, kdy může být daná lexikální jednotka použita jakožto vyslovení nějakého syntaktického uzlu:
(4) Princip nadmnožiny:
Strom uložený v lexikonu se shoduje se syntaktickým stromem tehdy a jen tehdy, když obsahuje daný syntaktický uzel.
Princip nadmnožiny může být ilustrován na příkladě synkretismu anglického morfému ‑ed (✍Starke, 2002; ✍Starke, 2005; ✍Starke, 2009). Tento sufix má jak aktivní význam (He danc‑ed ‘Tancoval’, He fold‑ed the sheet ‘Poskládal prádlo’), tak pasivní význam (The sheets were fold‑ed ‘Prádlo bylo poskládáno’). Je obecně přijímáno, že tyto významy jsou ve vztahu pod/nadmnožiny: pasivní význam je „nedokonalým“ protějškem věty aktivní, protože jí chybí agens; v důsledku je tedy menší, neboť jí chybí rys vyjadřující personálního původce děje (a tedy i odpovídající funkční projekce). Princip nadmnožiny (4) pak umožňuje, aby jeden morfém (‑ed), specifikovaný jako minulá změna způsobená nějakým agentem (= aktivní ‑ed), byl rovněž použit k vyslovení menší struktury (změna bez personálního původce děje). Odtud pak plyne synkretismus těchto dvou verbálních kategorií.
Princip nadmnožiny stojí v přímém protikladu k tzv. principu podmnožiny (subset principle; např. ✍Hale & Reiss, 2003), známému z ↗DM. Podle něho může být lexikální jednotka použita k vyslovení nějakého uzlu tehdy a jen tehdy, pokud rysy lexikální jednotky jsou podmnožinou rysů daného uzlu. Podle principu nadmnožiny se jedná o nadmnožinu:
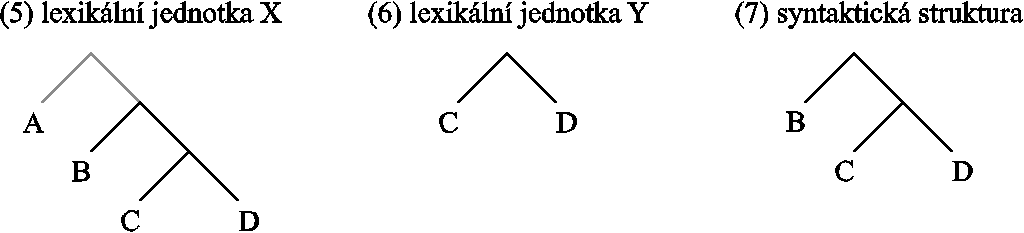
Představme si nyní, že syntax vytvoří strukturu (7). Představme si dále, že máme dvě lexikální jednotky (5) a (6). V DM by struktura (7) byla vyslovena pomocí lexikální jednotky (6). V n. je tato struktura vyslovena pomocí jednotky (5): ta totiž danou strukturu obsahuje (i když má navíc rys A); jinými slovy (5) je nadmnožinou (7).
Takovýto systém vede k tomu, že lexikální jednotky mohou spolu soupeřit o to, která z více shodujících se jednotek bude použita k vyslovení struktury. Např. může nastat situace, kdy struktura (7) může být vyslovena pomocí lexikální jednotky Y ze (6) a nějaké další, která vysloví zbývající rys B. Anebo může být tato struktura vyslovena jako jeden celek pomocí lexikální jednotky X z (5). V takových situacích podle ✍Starkeho (2009) rozhoduje pravidlo, které nazývá „vyhrává ten největší“:
(8) Ten největší (lexikální zápis) vyhrává (nad více menšími).
Podle Starkeho vyplývá pravidlo (8) z cyklické povahy procesu vyslovování syntaxe. Cyklicita znamená, že k vyslovování struktury dochází opakovaně po každé operaci ↗merge. Konkrétně dochází k tomu, že po každé operaci merge je struktura předána do lexikonu k vyslovení, který poskytne shodující se lexikální jednoky pro danou strukturu. Tato procedura se opakuje po každé takové operaci, takže fonologická realizace menší struktury je vždy nahrazena realizací větší struktury (tedy zvětšené o nově „mergovaný“ rys).
Poslední princip, který potřebujeme, reguluje soupeření dvou jednočlenných lexikálních realizací. Předpokládejme, že syntax vytvoří strukturu [ C D ]. Tato struktura je obsažena jak v lexikální jednotce X (5), tak Y (6). Obě lexikální jednotky se shodují se strukturou [ C D ], protože ji obsahují. V tomto případě vyhraje lexikální jednotka Y: představuje totiž tu nejlepší možnou shodu podle principu (9) (kterému se v n. říká různými jmény):
(9) Minimalizuj odpad / Princip nejlepší shody
Pokud se víc lexikálních jednotek shoduje s daným uzlem, vyhraje ta, která má nejméně nevyužitých uzlů.
V kontextu ostatních předpokladů v teorii n. je (9) příkladem tzv. ↗elsewhere condition. Podle principu nadmnožiny má totiž jednotka s menším počtem nevyužitých uzlů omezenější distribuci, a je tedy nejvíc specifická.
Ve zkratce lze tedy definovat n. jako teorii, která používá principy (4), (8) a (9) a zároveň i myšlenku, že rysy (a ne lexikální jednotky) jsou základním stavebním kamenem syntaxe. Tyto hypotézy umožňují formulovat jednoduchou a prediktivní teorii ohledně možností a mezí morfosyntaxe, synkretismu a vztahu mezi lexikonem a syntaxí. Konkrétně byly tyto analytické zásady využity při popisu synkretismu v pádu (✍Caha, 2009, využívající i data z č.) a při popisu komplikovaného systému shody v bantuských jaz. (✍Taraldsen, 2010).
Jedna z oblastí, kde frazální lexikální jednotky používané v n. poskytují jednoduché řešení známého lingvistického problému, jsou ↗idiomy (např. natáhnout bačkory). Bez frazálních lexikálních jednotek se existence idiomů těžko vysvětluje. Jelikož ale v n. mohou lexikální jednotky odpovídat celým konstituentům, můžeme do lexikonu jednoduše přidat i celou idiomatickou verbální frázi s nekompozicionálním významem ‘umřít’; viz zvláště ✍Starke (2011). Na základě idiomů Starke rovněž zdůvodňuje svoji cyklickou koncepci procesu lexikalizace (vyslovování) struktury. Jelikož natáhnout bačkory má idiomatickou interpretaci, zatímco natáhnout papuče ji nemá, lexikalizace celé VP potřebuje vědět, jak dopadla lexikalizace uzlů v ní obsažených. Proto musí lexikalizace probíhat cyklicky odspodu nahoru. ✍Starke (2011) rovněž tvrdí, že vyslovování struktury probíhá nejen cyklicky odspodu nahoru, ale rovněž dochází k prolínání cyklu vyslovení s další syntaktickou komputací; takže ve výsledku je struktura vyslovena, předána k další komputaci (přidání rysu, posun), a pak opět k vyslovení, a tak dále až do konce; viz (2).
Dalším novým elementem teorie n. je způsob, jakým fungují parametry. V rámci chomskyánské ↗teorie principů a parametrů se předpokládá, že rozdíly mezi jazyky jsou nějakým způsobem způsobeny rozdílnými lexikálními jednotkami; viz ✍Borer(ová) (1984). V současné podobě ↗minimalismu se tento požadavek technicky implementuje především tak, že jednotlivé lexikální jednotky jsou anotovány pomocí ↗EPP rysů, neinterpretovatelných rysů atp. N. se pokouší o alternativní pohled, kdy jsou podobné konstrukty opuštěny a nahrazeny koncepcí, kdy lexikální jednotky mají různou velikost a tvar, což díky interakci lexikonu a syntaxe (viz 2) vede k tomu, že komputace probíhá odlišně v různých jaz.; viz ✍Starke (2011).
V rámci n. existují dvě různé interpretace myšlenky, že lexikální jednotky mohou odpovídat více než jednomu terminálnímu uzlu. V rámci přístupu nazývaném spanning (rozpětí) (✍Abels & Muriungi, 2008; ✍Taraldsen, 2010) se předpokládá, že terminální uzly vyslovené lexikální jednotkou nemusí tvořit konstituent. V rámci koncepce prosazované ve Starkeho pracích (frázový spell out) tyto terminální uzly však konstituent tvořit musí. Právě tento požadavek představuje způsob, jak lexikon daného jazyka může ovlivnit jeho syntax. Představme si např., že nějaký jazyk J má strukturu [ x [ y [ z ]]]. Předpokládejme dále, že výrazové prostředky tohoto jazyka (jeho lexikální jednotky) odpovídají strukturám [ z ] (lexikální jednotka A) a [ x [ y ]] (lexikální jednotka B). Jak tento jazyk vysloví danou strukturu za pomoci svých lexikálních jednotek? Tento jazyk nejprve vysloví spodní rys z jako A. Všimněme si však, že zbývající rysy x a y (obsažené v lexikální jednotce B) netvoří v syntaktické struktuře konstituent, nemohou být tedy společně vysloveny jako B. Starkeho myšlenka tedy je, že syntax provede posun rysu z tak, aby se dostal ven z konstituentu obsahujícího x a ; viz (9). Po posunu z tvoří x a y konstituent (tučně), který je vysloven jako B, a seřazení lexikálních jednotek je tedy A před B (nikoliv B před A).
(9) [ x [ y [ z ]]] → [ [ z ] [ x [ y ]]] → [ A [ B ]]
V důsledku tedy požadavek, a sice aby lexikalizované rysy tvořily konstituent, vede k možnosti toho, aby lexikalizace vyvolala posun (tzv. spell‑out driven movement). Tento závěr potřebuje navíc ještě předpoklad, že všechny rysy musí být lexikalizovány; viz ✍Fábregas (2007), ✍Ramchand(ová) (2008).
Předpokládejme dále, že nějaký jiný jazyk J´ má lexikální jednotku A odpovídající rysu struktuře [ y [ z ]] a lexikální jednotku B odpovídající rysu X. V jazyce J’ neexistuje důvod pro posun z; všechny rysy tvoří potřebné konstituenty už v bázové struktuře. Ve výsledku tedy existuje v prvním jazyce (tj. v jazyce J) posun, který v jazyce J’ není, což se empiricky projevuje tím, že J má seřazení A‑B, zatímco J‘ má seřazení B‑A. Vidíme tedy, že pokud lexikální jednotky mohou vyvolávat posun za účelem úspěšné lexikalizace, pak lze některé rozdíly mezi jazyky vztáhnout přímo k daným lexikálním jednotkám.
N. je jednou z vlivných lingvistických teorií, se kterou se seznámili čeští lingvisté školící se v Tromsø; mezinárodní význam má zvl. ✍Caha (2009).
- Abels, K. & P. Muriungi. The Focus Marker in Kîîtharaka: Syntax and Semantics. Lga 118, 2008, 687‒731.
- Baker, M. C. Lexical Categories: Verbs, Nouns and Adjectives, 2003.
- Borer, H. Parametric Syntax: Case Studies in Semitic and Romance Languages, 1984.
- Caha, P. The Nanosyntax of Case. PhD. diss., University of Tromsø, 2009.
- Caha, P. Explaining the Structure of Case Paradigms by the Mechanisms of Nanosyntax. NLLT 31, 2013, 1015‒1066.
- Cinque, G. Adverbs and Functional Heads. A Cross-linguistic Perspective, 1999.
- Fábregas, A. The Exhaustive Lexicalisation Principle. Nordlyd 34.2, 2007.
- Hale, M. & Ch. Reiss. The Subset Principle in Phonology: Why the Tabula Can’t Be Rasa. Journal of Linguistics 39, 2003, 219‒244.
- Chomsky, N. Remarks on Nominalization. In Jacobs, R. & P. Rosenbaum (eds.), Readings in English Transformational Grammar, 1970, 184‒221.
- Kayne, R. S. Some Notes on Comparative Syntax, with Special Reference to English and French. In Cinque, G. & R. S. Kayne (eds.), The Oxford Handbook of Comparative Syntax, 2005, 3‒69.
- Lundquist, B. Nominalizations and Participles in Swedish. PhD. diss., University of Tromsø, 2008.
- Pantcheva, M. Directional Expressions Cross‑linguistically: Nanosyntax and Lexicalization. Nordlyd 36.1, 2009, 7‒39.
- Ramchand, G. C. Verb Meaning and the Lexicon: A First Phase Syntax, 2008.
- Son, M. & P. Svenonius. Microparameters of Cross‑linguistic Variation: Directed Motion and Resultatives. In Abner, N. & J. Bishop (eds.), Proceedings of the 27th West Coast Conference on Formal Linguistics, 2008, 388‒396.
- Starke, M. The Day Syntax Ate Morphology. Přednášky na EGG, Novi Sad, 2002.
- Starke, M. Nanosyntax. Seminář na CASTL, University of Tromsø, 2005.
- Starke, M. Nanosyntax: A Short Primer to a New Approach to Language. Nordlyd 36.1, 2009.
- Starke, M. Toward Elegant Parameters: Language Variation Reduces to the Size of Lexically Stored Trees, 2011 (http://ling.auf.net/lingbuzz/).
- Taraldsen, K. T. The Nanosyntax of Nguni Noun Class Prefixes and Concords. Lga 120, 2010, 1522‒1548.
- Taraldsen, K. T. & L. Medová. The Czech Locative Chameleon. Nordlyd 34.2, 2007, 300‒319.
URL: https://www.czechency.org/slovnik/NANOSYNTAX (poslední přístup: 25. 4. 2024)
CzechEncy – Nový encyklopedický slovník češtiny
Všechna práva vyhrazena © Masarykova univerzita, Brno 2012–2020
Provozuje Centrum zpracování přirozeného jazyka