FONOTAKTIKA
Část fonologického popisu jazyků, která se zabývá fonotaktickými komplexy (fonotaktickým systémem), výskytem (↗distribucí), kombinovatelností a syntagmatickými vztahy fonologických jednotek uvnitř těchto komplexů. Jejím cílem je určit a vysvětlit zákonitosti výskytu a kombinovatelnosti formálních jaz. prostředků sloužících ke komunikaci. Termín f. se poprvé objevil v 50. letech 20. stol. v americké lingvistice (viz ✍Sigurd, 1968), ale zájem o syntagmatický aspekt fonologických systémů je starý a obvykle byl zahrnut pod studium kombinovatelnosti fonémů (viz ✍Trubetzkoy, 1939). Někdy se mluví o fonologické gramatice, protože stejně jako se gramatika, resp. syntax, zabývá gramatičností syntaktických struktur, tak se fonotaktika zabývá gramatičností fonotaktických struktur. Ve funkční fonologii je f. spolu s ↗fonématikou a ↗para‑fonotaktikou (prozodií) jedním ze základních aspektů fonologického popisu jaz. (↗axiomatický funkcionalismus).
Fonotaktický komplex je uspořádaný svazek fonémů a lze jej nazvat fonotagma (stejně jako se termínem ↗syntagma označuje syntaktický komplex). Fonotagma je ve f. maximální jednotkou a foném jednotkou minimální. Fonémy se dále analyzují ve fonématice na distinktivní rysy. Soubory fonotagmat se zpravidla pojí s dalšími fonologickými rysy jako tóny či přízvuk, a jsou proto analyzovány v para‑fonotaktice. Soubory fonotagmat odpovídají ↗fonologickým slovům, ↗přízvukovému taktun. jiným para‑taktickým (prozodickým) jednotkám. Jeden z úkolů strukturně funkční f. je proto určit, ze kterých fonotagmat se takové jednotky skládají. V přístupech, které pracují se slabikou jako základní fonotaktickou jednotkou, se mluví o ↗slabikování. Pravidla slabikování se ovšem liší a neexistuje jednotná koncepce (viz ✍Bell, 1976).
Na fonotaktické úrovni je fonotagma soběstačnou (autonomní) uspořádanou množinou fonémů dále nedělitelnou na menší soběstačné množiny fonémů (viz ↗funkční uspořádání). Fonotagmatem může být i jednoduchý foném jako např. /a/ v č. (srov. slovo a). Množina fonémů je soběstačná, jestliže odpovídá fonologické formě promluv (je tedy přímo doložena), n. jestliže není její struktura v rozporu se strukturou přímo doložených fonologických forem. Proto v č. např. /klavīr/ obsahuje fonotagmata /kla/ a /vīr/. Fonotagma /vīr/ je doloženo jako forma slova vír, ale /kla/ přímo doloženo není. Přesto lze v č. /kla/ pokládat za správně utvořené fonotagma, jelikož není v rozporu se strukturou přímo doložených fonologických forem (srov. /kli/ kly, /klam/ klam). Jakékoliv další dělení komplexů /kla/ a /vīr/ však vede alespoň k jedné formě, jež je v rozporu s distribučními vlastnostmi č. Např. dělíme‑li /vīr/ na /vī/ a /r/, pak dostaneme /r/, avšak tento foném nemůže v č. stát sám o sobě, poněvadž se ve fonologických formách slov vždy objevuje s alespoň jedním dalším fonémem. Proto jsou /kla/ a /vīr/ minimálními, dále nedělitelnými soběstačnými fonotaktickými komplexy.
Fonotagmata neboli komplexy fonémů lze popsat pomocí abstraktního systému pozic, přičemž pozice je syntagmatické místo, které může být zaplněno jednotkou z paradigmatického systému (fonémem). Různá zaplnění pozic pak odpovídají těmto komplexům. Toto je nejčastější způsob fonotaktického popisu jaz., avšak jednotlivé přístupy se liší v pojetí pozic, které bývají chápány buď relativně, n. absolutně. Relativně pojatá pozice je definována ve vztahu k jiným pozicím (např. první pozice před nukleární pozicí) n. k hranicím jednotek (např. počáteční pozice slabiky). Pro č. takový přístup zvolil ✍Kučera (1961), revidovaný model nabízí ✍Bičan (2013), kap. 17, pro jiné jaz. viz např. ✍Haugen (1956), ✍Sigurd (1956).
Při absolutním chápání pozic je počet pozic pevně daný a odpovídá maximálním kombinačním schopnostem fonotaktických komplexů. V tomto přístupu může být pozice zaplněna buď fonémem z určité paradigmatické třídy, n. může být prázdná. Prázdná pozice odkazuje na fakt, že některé fonémy je možné nahradit nulou, aniž by výsledný soubor fonémů přestal být soběstačný (tj. gramatický), srov. např. /tam/ oproti /ta/, tj. /taØ/. Tento přístup na č. aplikoval ✍Bičan (2013), na jiné jaz. např. ✍Mulder (1968), ✍Rastall (1993), na angličtinu ✍Fudge (1969).
Abstraktní systém pozic můžeme nazvat distribuční jednotkou, jiní mluví o (slabičných) templátech (např. ✍Selkirk(ová), 1982). Ve funkčním přístupu distribuční jednotka označuje svazek absolutních pozic ve výše uvedeném smyslu. Pozice distribuční jednotky nejsou zaplněny libovolně, jelikož daný jaz. některé kombinace fonémů nemusí dovolovat (např. č. kombinace dvou velár vedle sebe v rámci jednoho fonotagmatu/slabiky), a proto je součástí každého fonotaktického popisu stanovení podmínek souvýskytu fonémů. Fonotagma je potom jedna z možností, jak lze pozice distribuční jednotky zaplnit.
Distribuční jednotka je takový svazek pozic, pomocí něhož je možné popsat výskyt a kombinovatelnost fonémů daného jaz. vyčerpávajícím způsobem. Tradičně se předpokládá, že takovou jednotkou je ↗slabika, resp. slabičný templát (✍Pike, 1947; ✍Fischer‑Jørgensen(ová), 1952; ✍Haugen, 1956; ✍Zec(ová), 2007). Nicméně v mnoha jaz. není slabika schopna popsat všechny výskyty fonémů a lingvisté pro fonotaktický popis volí jiné jednotky, např. morfém (✍Trubetzkoy, 1939) n. slovo (✍Mathesius, 1929; ✍Vachek, 1940, pro č.). Např. v některých australských jaz. jsou slova zpravidla dvouslabičná a výskyt konsonantů v druhé slabice slova je jiný než v slabice první (✍Dixon, 1980). Kompletní popis výskytů fonémů tam tudíž vyžaduje dvouslabičnou jednotku.
Na nutnost pracovat s komplexnějšími distribučními jednotkami než slabika upozornil již ✍Mulder (1968) a na nedostatečnost fonotaktického popisu založeného na slabice též poukázali jiní s příklady z dalších jaz. včetně angličtiny, italštiny nebo japonštiny (✍Blevins(ová), 2003). Je tedy vhodnější mluvit o fonotagmatu jako realizaci distribuční jednotky s tím, že fonotagma může, ale nemusí být totožné se slabikou. V č. se fonotagma a slabika shoduje až na případy jako /Stārl/ (srov. stárl). Slovo stárl je vnímáno jako dvouslabičné, ale distribučně je výskyt /l/ závislý na /ā/, a proto se jedná o jedno fonotagma (viz ✍Bičan, 2013, kap. 10, ✍Bičan, 2014).
Podobně jako funkčněsyntaktický popis i funkčněfonotaktický popis vychází z předpokladu, že lze rozlišit mezi jednotkami (tj. fonémy), jež jsou nukleem (tj. jádrem) fonotaktických komplexů, a jednotkami, jež jsou na nich ↗funkčně závislé. Výskyt fonému prvního typu je nutnou podmínkou pro gramatičnost fonotaktického komplexu, zatímco přítomnost fonému druhého typu nemusí nutně gramatičnost ovlivňovat a lze ho zpravidla nahradit nulou. Např. v komplexu /doj/ je /o/ nukleárním fonémem, protože jeho výskyt je nutný (/dj/ není v č. fonotagmatem), kdežto /d/ a /j/ jsou ne‑nukleární (periferní) fonémy, protože jejich výskyt nutný není (/do/, /oj/ a /o/ jsou v č. fonotagmata, srov. slova do, oj, o). Některé fonotaktické komplexy však mohou vyžadovat přítomnost jak nukleárního, tak periferního fonému a nukleárnost je nutné určit jinak. To je případ nukleárních /r/ a /l/ v č. ve slovech prst, vlk. Kromě fonotaktických komplexů obsahujících vokál č. dovoluje komplexy bez vokálu. Necháme‑li stranou formy předložek s a z, pak takové komplexy vždy obsahují /r/ n. /l/ a zároveň alespoň jeden další foném (konsonant, např. /hr/ – být hr). V těchto komplexech jsou /r/ a /l/ nukleární, jelikož je lze nahradit jen jinými nukleárními fonémy (srov. prst × plst, ale nikoliv *pmst), zatímco ostatní fonémy lze nahradit jak nukleárními fonémy (srov. prst × prsa), tak periferními fonémy (srov. prst × prsť).
Nukleárnost jakožto fonotaktická funkce tedy není nutně závislá na slabičnosti, ale vyplývá z podmínek výskytu fonémů. Proto je možné stanovit různé třídy fonémů podle jejich fonotaktické funkce, stejně jako je možné určit různé třídy syntaktických konstituentů podle jejich syntaktické funkce. Fonémy mohou být vždy nukleární, vždy nenukleární, n. mohou plnit obě funkce. V konkrétních jaz. se situace liší. Fonémy prvního typu bývají tradičně označovány vokály a fonémy druhého typu pak konsonanty. Konečně fonémy třetího typu můžeme nazvat semivokály nebo semikonsonanty. V č. sem patří /r/ a /l/; mnohé jaz. však tyto fonémy nemají, byť jsou časté (✍Bell, 1978). Uvedené termíny označují fonologické třídy, nikoliv hlásky s určitými artikulačními či akustickými vlastnostmi. Vokály se nicméně zpravidla realizují jako ↗vokoidy a konsonanty jako ↗kontoidy a semikonsonanty jako ↗aproximanty n. ↗sonory.
Fonotaktické komplexy obsahují právě jeden nukleární foném a ostatní fonémy jsou periferní (ne-nukleární). Jelikož má řeč lineární povahu, lze rozlišit mezi periferními fonémy před nukleem (= prenukleárními) a periferními fonémy za nukleem (= postnukleárními) a zároveň určit míru jejich perifernosti podle jejich vzdálenosti od nuklea: /S→t→r→a←S←T/ (srov. č. strast; šipky označují funkční závislost, velká písmena ↗archifonémy). Zdá se, že přirozené jaz. preferují výskyt periferních fonémů v prenukleárním kontextu spíše než v kontextu postnukleárním. Tvrdí se, že existují jaz., které postnukleární fonémy nedovolují, zatímco jaz., které nedovolují prenukleární fonémy, téměř neexistují. Příklady jsou ovšem nejednoznačné a vždy záleží na konkrétní interpretaci jaz. dat (viz ✍Bičan, 2011). Možným případem jaz. bez periferních fonémů může být ↗praslovanština před ztrátou ↗jerů. V č. je jasně patrná tendence k výskytu periferních fonémů (konsonantů) na začátku fonotagmat a navíc se prenukleární fonémy vyznačují větší kombinovatelností než fonémy postnukleární (viz níže).
Základním problémem f. je popis kombinací fonémů n. jiných fonologických jednotek. Stejně jako v syntaxi se totiž nabízí otázka, které kombinace jsou v jaz. možné (gramatické) a které nikoliv. Na jedné straně jaz. nedovolují libovolné kombinace fonémů a např. slovo s formou /mtmntnr/ je v č. velmi nepravděpodobné. Na straně druhé nemůžeme tvrdit, že v jaz. jsou možné jen ty kombinace, které jsou přímo doložené, protože běžně vznikají zcela nová slova s nedoloženými kombinacemi fonémů (např. mlslo jako název krému z dýní, másla a vanilky). Fonotaktická analýza by proto měla zahrnovat nejen popis doložených kombinací, ale také popis potenciálně možných, avšak nedoložených kombinací a nemožných kombinací. Není ovšem jasné, zda hranici mezi nemožnými a potenciálně možnými kombinacemi lze přesně určit a jakým způsobem (viz ✍Spang‑Hansen, 1959). Navíc se zdá, že mluvčí nehodnotí nedoložené kombinace fonémů buď jako možné, n. nemožné, ale jako přijatelnější n. méně přijatelné (viz ✍Scholes, 1966; ✍Frisch & Large ad., 2000, ✍Hay & Pierrehumbert(ová) ad., 2003).
1
V pojetí funkční fonologie má č. fonémy, které jsou vždy nukleární, tj. vždy tvoří jádro (nukleus) fonotagmatu (= vokály), fonémy, které jsou vždy periferní, tj. nikdy netvoří jádro fonotagmatu (= konsonanty), a fonémy, které mohou být jak nukleární, tak periferní (= semikonsonanty /r/ a /l/), viz výše a ↗fonématika češtiny. Pro zjednodušení bude v dalším výkladu termín nukleární foném označovat vokály a nukleární („slabičné“) semikonsonanty a termín konsonant bude označovat konsonanty a nenukleární („neslabičné“) semikonsonanty.
Fonotagma obsahuje právě jeden nukleární foném a může obsahovat několik konsonantů jak před nukleárním fonémem, tak za ním. V prenukleárním kontextu je možných maximálně pět konsonantů (/FSkvjeT/ vzkvět; velká písmena označují ↗archifonémy), obvyklejší je však výskyt jednoho až čtyř konsonantů (/sen/ sen, /tma/ tma, /StraX/ strach, /PStruX/ pstruh), n. fonému žádného (/on/ on). Postnukleární kontext umožňuje výskyt jednoho až tří konsonantů (/leS/ les, /uST/ uzd, /pomST/ pomst). Jsou možná i fonotagmata končící jen na nukleární foném (/to/ to), a ta jsou daleko častější než fonotagmata zakončená na jeden n. více konsonantů. Celkový počet konsonantů ve fonotagmatu je omezen na šest; nejsou doložena fonotagmata, která by obsahovala více konsonantů (tj. ne-nukleárních fonémů, podrobnosti viz ✍Bičan, 2013:kap. 8, ✍Bičan, 2015). Tabulka 1 shrnuje doložené typy fonotagmat (C označuje konsonant a V nukleární foném) a udává jejich procentuální zastoupení podle údajů z ↗Fonologického lexikálního korpusu češtiny. Mezi deset nejčastějších fonotagmat v č. lexiku patří (se snižující se frekvencí): /ťi/, /va/, /ka/, /ko/, /vī/, /po/, /vi/, /na/, /o/, /nī/. Viz též ✍Těšitelová ad. (1985).
Tab. 1: Doložené typy fonotagmat v č. a jejich procentuální zastoupení v č. lexikonu (950 890 fonotagmat ve 263 773 ↗lemmatech)
-Ø | -C | -CC | -CCC | Celkem | |
Ø- | V | VC | VCC | VCCC | 3,767 % |
C- | CV | CVC | CVCC | CVCCC | 72,003 % |
CC- | CCV | CCVC | CCVCC | CCVCCC | 22,102 % |
CCC- | CCCV | CCCVC | CCCVCC | CCCVCCC | 2,062 % |
CCCC- | CCCCV | CCCCVC | CCCCVCC | 0,063 % | |
CCCCC- | CCCCCV | CCCCCVC | 0,0003 % | ||
Celkem | 76,203 % | 19,788 % | 4,016 % | 0,093 % | 100 % |
Konsonanty v prenukleárním a postnukleárním kontextu tvoří kombinace, které se vyznačují značnou variabilitou. Na začátku fonotagmatu nalezneme více než 400 různých kombinací a na konci více než 100 různých kombinací. Jejich strukturu popisuje ✍Bičan (2013). Nejfrekventovanější jsou dvoučlenné kombinace, a to jak na začátku, tak na konci fonotagmatu. Tabulka 2 zobrazuje počty počátečních a koncových kombinací doložených v č. lexiku a jejich procentuální zastoupení podle údajů z ↗Fonologického lexikálního korpusu češtiny.
Tab. 2: Doložené typy počátečních a koncových kombinací v č. lexiku a jejich procentuální zastoupení (hodnoty pro 230 399 fonotagmat s počáteční kombinací a 39 072 fonotagmat s koncovou kombinací)
Počet konsonantů v kombinaci | |||||
2 | 3 | 4 | 5 | ||
Začátek | počet kombinací | 215 | 225 | 62 | 2 |
zastoupení | 91,22 % | 8,52 % | 0,26 % | 0,001 % | |
Konec | počet kombinací | 101 | 60 | – | – |
zastoupení | 97,73 % | 2,27 % | – | – | |
Nejčastějšími prenukleárními kombinacemi v č. lexiku je těchto deset kombinací (se snižující se frekvencí výskytu): /Ts/, /Tš/, /pr/, /př/, /Sk/, /tr/, /vj/, /kr/, /kl/, /tv/ (srov. cín, čert, práh, přes, skot, trám, věk, krást, klec, tvůj). Nejčastějšími postnukleárními kombinacemi je těchto deset: /TS/, /ST/, /TŠ/, /nS/, /nT/, /nK/, /rS/, /nTS/, /KS/, /lS/ (srov. pec, past, proč, trans, pant, tank, Mars, princ, koks, puls). Kombinace /Ts/, /Tš/, /TS/, /TŠ/ odpovídají afrikátám, které jsou fonologicky interpretovány jako skupiny konsonantů (viz ↗fonématika češtiny).
1.1 Distribuce fonémů
Fonémy se nekombinují libovolně a zákonitosti jejich výskytu lze popsat pomocí distribuční jednotky jakožto souboru absolutních pozic (viz výše). V č. se distribuční jednotka skládá z pěti prenukleárních, jedné nukleární a tří postnukleárních pozic. Počty odpovídají maximálnímu počtu fonémů v daných kontextech. Každá pozice může být zaplněna právě jedním fonémem a všechny kromě nukleární pozice mohou být též prázdné. Různá zaplnění pozic, ať už fonémem či nulou (v případě prázdné pozice), odpovídají doloženým nebo potenciálně možným fonotagmatům. Tabulka 3 nabízí celkovou podobu distribuční jednotky spolu s třídami fonémů, které se v nich mohou objevit. Symbol Ø označuje, že pozice může být prázdná.
Tab. 3: Distribuční jednotka pro češtinu
Prenukleární (počáteční) pozice | Nukl. pozice | Postnukleární (koncové) pozice | ||||||
P5 | P4 | P3 | P2 | P1 | N | K1 | K2 | K3 |
P F K X | T S Š ř | k g x h | v m Ø | r l | j r l | P T K | P T K | |
m n ň | i e a o u | |||||||
p b f | ||||||||
ť ď | m n ň r l | |||||||
Model vyjadřuje nejen pravidla výskytu fonémů v č., ale též jejich kombinační možnosti. Pro každý foném lze z modelu odvodit, kolik jiných fonémů může stát před a za ním (podle toho, kolik předchází n. následuje pozic) a také jaké fonémy to mohou být (jen ty, které patří do daných pozic). Např. za fonémy patřící do pozice P3 stojí maximálně dva konsonanty a těmi mohou být jen fonémy z pozice P2, tj. /v/ nebo /m/, a pozice P1, tj. /m/, /n/, /ň/, /j/, /ř/, /r/ nebo /l/. Následuje‑li za nimi pouze jeden konsonant, je to vždy jeden z fonémů patřící do pozic P2 nebo P1.
Fonémy, které jsou v tab. 3 umístěny v buňkách zasahujících do více pozic, náležejí do archipozic. ↗Archipozice vyjadřují, že některé fonémy mají ve srovnání s jinými fonémy omezenější kombinační schopnosti. Např. konsonanty /ť/ a /ď/ patří do archipozice ekvivalentní pozicím P1, P2 a P3. Tyto fonémy nikdy nestojí před fonémy ze zmíněných pozic, což znamená, že /ť/ a /ď/ vždy stojí před vokálem, a nikdy ne před jiným konsonantem. Nicméně stejně jako před jinými okluzivami mohou před /ť/ a /ď/ stát dva konsonanty, avšak jsou to jen ty, jež patří do pozic P4 a P5.
Distribuční jednotka formalizuje pravidla výskytu a kombinovatelnosti fonémů, avšak je nutné ji doplnit pravidly omezujícími souvýskyt fonémů (viz níže). Distribuční jednotku lze následně použít jako algoritmus pro kalkulování („generování“) doložených a potenciálně možných fonotagmat. Schéma 1 ukazuje algoritmus pro vokály a prenukleární kontext; schéma pro postnukleární kontext viz ✍Bičan (2013). Linky označují možnosti, mezi nimiž můžeme volit a dostat se k jednotlivým pozicím. Obdélníky označují množiny fonémů, z nichž můžeme v každé pozici volit.
Schéma 1: Algoritmus pro kalkulování prenukleárních kombinací v češtině
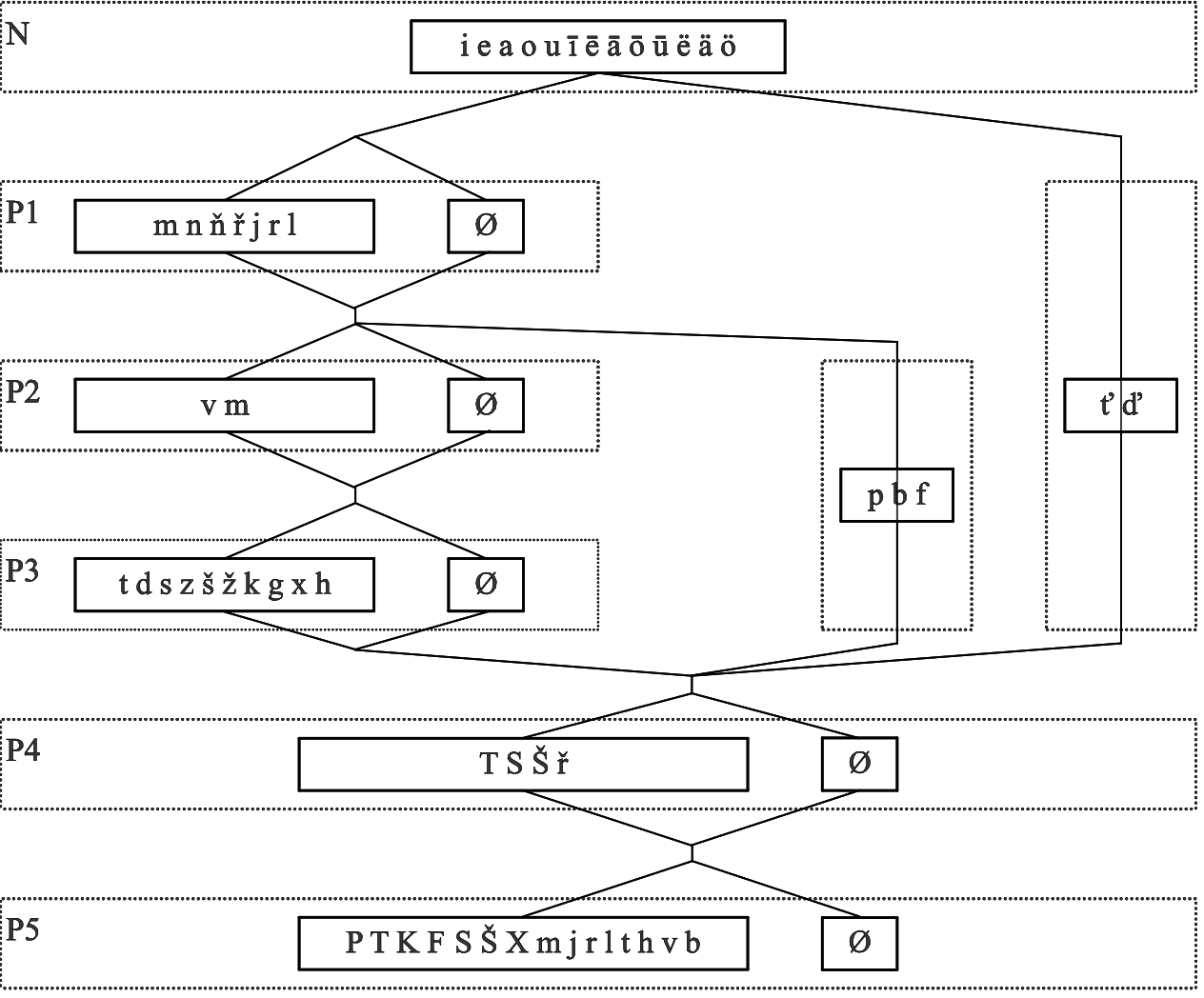
|
1.1.1 Výskyt fonémů v nukleární pozici
V č. jádro fonotagmatu tvoří buď vokály, n. semikonsonanty /r/ a /l/. Je‑li jádrem vokál, výskyt dalších fonémů není nutný (srov. /a/ a, /i/ i, /o/ o, /u/ u). Dlouhé a diftongální vokály se ovšem zpravidla samostatně neobjevují s výjimkou citoslovcí (srov. /ä/ au) n. názvů písmen (např. /ā/ á). Semikonsonanty jsou jádrem fonotagmatu, pouze pokud před nimi stojí alespoň jeden konsonant s výjimkou /ř/ a /j/ a za na nimi následuje další konsonant (např. /trn/ trn, /vlK/ vlk) n. semikonsonant (/Stārl/ stárl, /umrlTšī/ umrlčí, nukleární /r/ podtrženo) n. následuje-li konec fonologického slova (např. (být) hr, /hl/ z mihl). Foném /ř/ se nikdy s nukleárními semikonsonanty nekombinuje a stejně tak se s nimi nekombinuje /j/. Formy jako /xejr/ chejr a /hejl/ hejl nelze rozdělit na menší soběstačná fonotagmata, poněvadž kombinace /jr/ a /jl/ se nikdy nevyskytují samy o sobě, a jsou tedy v obou případech distribučně závislé na nukleárním /e/. V těchto formách nejsou tudíž semikonsonanty jádry samostatných fonotagmat (jejich fonetické realizace navíc nejsou pociťovány jako slabičné). Ze stejných důvodů nejsou semikonsonanty nukleární („slabičné“) ve formách /detajlňī/ detailní a /madejrSkī/ madeirský. Podobně není možné formu /Stārl/ stárl rozdělit na menší autonomní fonotagmata (/rl/ je distribučně závislé na /ā/), a tudíž ani zde /l/ není nukleární, byť některými uživateli č. bývá toto slovo vnímáno jako dvojslabičné (✍Bičan, 2014). Obdobně je interpretována forma /umrlTšī/ umrlčí, v níž je nukleární jen první semikonsonant /r/, ale nikoliv už /l/ (✍Bičan, 2013:140–155). Nukleárnost semikonsonantů je nutné stanovit v rozsahu jednoho fonologického slova, která je fonologickou doménou v další úrovni nad fonotagmatem (viz ↗para-fonotaktika). Ortografická slova jako zrdousit, zlhostejnět a předložková spojení jako v rtech, v lněném mají status dvou fonologických slov, čímž se odlišují od slov jako zrcadlo, slza n. vrtech a vlněném (viz ↗fonologické slovo). Stojí-li vedle semikonsonantu v rámci jednoho fonologického slova vokál, je nukleární on (např. /praK/ prak, /šel/ šel). Na rozhraní dvou fonologických slov však sousedství vokálů nukleárnost /r/ a /l/ neovlivňuje. Ve spojeních vítr ustal n. přinesl ovoce, která odpovídají dvěma fonologickým slovům, jsou semikonsonanty nukleární, i když za nimi následuje vokál.
Nukleární semikonsonanty náleží do archipozice ekvivalentní pozicím P1 a N. Tato archipozice vyjadřuje, že na rozdíl od vokálů mohou před /r/ a /l/ stát jen čtyři konsonanty. Tyto fonémy patří do pozic P2, P3, P4 a P5 (/TŠtvrT/ čtvrt). Před nukleárními semikonsonanty nikdy nestojí foném z pozice P1, tj. /n/, /ň/, /j/, /ř/, /r/, /l/. Výjimkou je nazála /m/, jež také patří do P1, avšak vyskytuje se i v pozici P2. Je to jediná nazála, která v č. stojí před semikonsonanty (a vůbec před konsonanty na začátku fonotagmatu, srov. /mrāS/ mráz, /mlŠ/ mlž).
Podle údajů z ↗Fonologického lexikálního korpusu češtiny vokály tvoří jádro 98,7 % všech fonotagmat (79,25 % krátké vokály, 17,67 % dlouhé vokály a 1,78% diftongální vokály); semikonsonantům odpovídá pouze 1,3 %.
1.1.2 Výskyt fonémů na začátku fonotagmatu
Na začátku fonotagmatu mohou všechny konsonanty stát před vokálem a dále všechny kromě /ť/, /ď/, /n/, /ň/, /ř/, /j/, /r/ a /l/ také před nukleárním semikonsonantem.
PRENUKLEÁRNÍ POZICE P1. Sem náleží fonémy /m/, /n/, /ň/, /j/, /ř/, /r/ a /l/. Před /j/ a /ň/ může stát jeden až čtyři fonémy z pozic P2, P3, P4, P5, popř. z archipozice ekvivalentní pozicím P2 a P3 (/j/: /pj/ pět, /kvj/ květ, /FSpj/ vzpěr, /FSkvj/ vzkvět; /ň/: /sň/ sní, /Shň/ shnít, /hřmň/ hřmět, /FSdmň/ vzdměte). Fonémy /m/, /n/, /ř/, /r/ a /l/ mají obdobné kombinační možnosti, avšak před nimi jsou doloženy maximálně tři konsonanty (/m/: /sm/ smích, /Stm/ stmívat se, /FSdm/ vzdmout; /n/: /pn/ pne, /Sxn/ schnout, /lStn/ lstný; /ř/: /kř/ křik, /Stř/ střih, /PStř/ pstřeň; /r/: /dr/ druh, /smr/ smrad, /PŠtr/ pštros; /l/: /xl/ chlap, /svl/ svlačec, /FStl/ vztlak).
PRENUKLEÁRNÍ POZICE P2. Sem patří /v/ a /m/. Foném /m/ je jediná nazála, která na začátku fonotagmatu stojí před konsonantem (/mň/ mnich), nebo mezi dvěma konsonanty (/sml/ smlouva, /hřmň/ hřmět, /FSdmň/ vzdměte). Distribuce /v/ je obdobná (/vň/ vnikl, /svr/ svrab, /Skvj/ skvěl, /FSkvj/ vzkvět).
PRENUKLEÁRNÍ POZICE P3. Sem patří fonémy /t/, /d/, /s/, /z/, /š/, /ž/, /k/, /g/, /x/ a /h/. Mezi nimi a nukleárním fonémem může stát jeden konsonant z pozice P2, nebo P1 (/tv/ tvor, /dr/ druh, /sm/ smír, /zv/ zvát, /šn/ šnek, /žm/ žmoulat, /kř/ křest, /gr/ gram, /xm/ chmury, /hň/ hnít). Mohou za nimi stát také dva konsonanty z pozic P2 a P1 (/tmň/ tmě, /dvj/ dvě, /smň/ směna, /zmr/ zmrazit, /kvj/ květ, /xvj/ chvět, /hvj/ hvězd). To však platí jen pro fonémy /t/, /d/, /s/, /z/, /k/, /x/ a /h/, poněvadž za /š/, /ž/ a /g/ je doložen pouze jeden konsonant. Ve všech uvedených případech před fonémy z pozice P3 může stát jeden, nebo dva fonémy z pozic P4 a P5 (/t/: /Ft/ vtáhnout, /FSt/ vstát; /d/: /Sdr/ sdružení, /FSd/ vzdát; /s/: /Tsv/ cval, /STs/ scestný; /z/: /Fz/ vzít; /š/: /rTš/ rčení, /FTš/ včleň; /ž/: /Sž/ zženštilý, /STž/ zdžezovat; /k/: /Skl/ sklad, /FSk/ vzkaz; /g/: /Sg/ zgalvanizovat; /x/: /Fx/ vchod, /FSxl/ vzchlípnout; /h/: /Shř/ zhřešit, /FShl/ vzhlížet). Před /g/ a /z/ nejsou doloženy dva konsonanty, ale jen jeden.
PRENUKLEÁRNÍ ARCHIPOZICE EKVIVALENTNÍ POZICÍM P2 A P3. Sem patří labiály /p/, /b/, /f/, které se distribučně odlišují od ostatních labiál /m/ a /v/. Před /p/ a /b/ mohou stát maximálně dva konsonanty z pozic P4 a P5 (/FSp/ vzpour, /Xřb/ hřbet), zatímco před /m/ a /v/ mohou stát maximálně tři konsonanty (viz výše). Před /f/ je doložen jen jeden konsonant, a to buď z pozice P4 (/Sf/ sfouknout), n. z pozice P5 (/Kf/ Kfely (název obce)). Také před /p/ a /b/ může stát jeden foném z těchto pozic (/Fp/ vpít, /Sb/ sbor). S /m/ a /v/ se však /p/, /b/, /f/ shodují v tom, že za nimi může stát maximálně jeden konsonant z pozice P1 (/pj/ pět, /bř/ břeh, /fň/ fňukat).
PRENUKLEÁRNÍ ARCHIPOZICE EKVIVALENTNÍ POZICÍM P1, P2 A P3. Sem patří palatální okluzivy /ť/ a /ď/, které vždy stojí před vokálem (/ťel/ těl, /ďīK/ dík). Předcházet je může jeden konsonant z pozice P4, n. P5 (/Šť/ štít, /Fď/ vděk), n. dva fonémy z pozic P4 a P5 (/Křť/ křtin, /mSď/ mzdě).
PRENUKLEÁRNÍ POZICE P4. Zde se objevuje foném /ř/, jenž rovněž patří i do pozice P1. Jeho příslušnost do pozice P4 je omezena na případy, kdy za ním stojí další konsonant (maximálně dva: /řk/ řka, /řvj/ řvěte), n. když stojí mezi dvěma konsonanty (tj. kombinace C1řC2). Pokud je konsonantem C2 vpravo od /ř/ okluziva nebo frikativa, levý konsonant C1 podstupuje ↗neutralizaci znělosti (/Xřb/ hřbet, /Křť/ křtin, /Třp/ třpyt). Je‑li pravým konsonantem C2 nazála (doloženo jen /m/) n. /v/, k neutralizaci nedochází (/hřmň/ hřmění, /břv/ Břve (název obce)). Do P4 také patří okluziva /T/ a frikativy /S/ a /Š/. Za /T/ a /S/ může stát jeden až tři fonémy z pozic P3, P2 či P1, pro /Š/ jsou doloženy jenom fonémy dva (/T/: /Tk/ tkát, /Tkn/ tknout, /Tkvj/ tkvěl; /S/: /Sb/ sbor, /Spl/ splav, /PStr/ pstruh; /Š/: /Šť/ štít, /Štv/ štvát). Před všemi může stát jeden foném z pozice P5 (/T/: /STkvj/ v archaickém stkvět; /S/: /FSkvj/ vzkvět; /Š/: /FŠd/ vždy). Jak je patrno, /ř/ je distribučně podobné jednak ostatním sonantám, především /r/ a /l/ (pozice P1, viz výše), jednak frikativám /S/ a /Š/ a okluzivě /T/.
PRENUKLEÁRNÍ POZICE P5. Fonémy /T/, /S/ a /Š/ patří též do pozice P5, ale jenom stojí-li před fonémem z pozice P4. Okluziva /T/ se vyskytuje pouze před /ř/, /S/ a /Š/ (/Třp/ třpyt, /TSp/ cpát, /TŠk/ Čkyně (název obce)). Frikativy /S/ a /Š/ stojí jen před /T/ (/STkl/ ztklivět, /ŠTk/ štkát). Do P5 patří také /m/, /j/, /r/ a /l/. Všechny mohou předcházet jeden n. více konsonantů. Po /m/ a /l/ jsou doloženy maximálně tři konsonanty (/m/: /mš/ mše, /mdl/ mdlo, /mStn/ mstný; /l/: /lz/ lze, /lpj/ lpět, /lStn/ lstný), po /j/ a /r/ jen dva (/j/: /jď/ jdi, /jmň/ jmění; /r/: /rt/ rty, /rTš/ rčení). V takových kombinacích jsou uvedené fonémy vždy na začátku fonotagmatu a jejich výskyt se tradičně popisuje jako ↗pobočné slabiky. V č. je doloženo nejméně 54 takových kombinací (viz ✍Bičan, 2013:149).
Kromě již popsaných případů patří do P5 též /P/, /F/, /K/, /X/ a /v/, /t/, /h/, /b/. Archifonémy /P/, /F/, /K/ a /X/ se v prenukleárním kontextu nikde jinde nevyskytují. Po /P/ může stát jeden až tři konsonanty (/Pt/ pták, /PSď/ bzdít, /PStr/ pstruh), po /F/ jeden až čtyři konsonanty (/Fp/ vpálit, /FSk/ vzkaz, /FSpř/ vzpřímit, /FSkvj/ vzkvět), po velárách /K/ a /X/ však jen maximálně dva (/K/: /Kt/ který, /Křť/ křtiny; /X/: /Xb/ hbitý, /Xřb/ hřbet). Konsonanty /t/ a /h/ se primárně vyskytují v pozici P3, konsonant /v/ v pozici P2 a konsonant /b/ v archipozici ekvivalentní pozicím P3 a P2. Všechny se mohou objevit v P5, ale jenom v několika kombinacích (např. /vml/ vmlátit, /třm/ třmen, /hřm/ hřmí, /břv/ Břve).
1.1.3 Výskyt fonémů na konci fonotagmatu
Okluzivy a frikativy podstupují na konci fonotagmat ↗neutralizaci znělosti. Bezprostředně po nukleárním fonému se objevují všechny konsonanty kromě /j/ a /ř/, které nejsou možné po nukleárních semikonsonantech.
POSTNUKLEÁRNÍ POZICE K1. Sem patří /m/, /n/, /ň/, /j/, /r/, /l/. Za všemi může stát jeden konsonant z pozice K1, n. K2 (/mP/ lamp, /nŠ/ jenž, /ňK/ šizuňk, /jT/ prejt, /rS/ kurz, /lX/ valch). Po /j/, /r/ a /l/ může též stát jeden konsonant z archipozice ekvivalentní K2 a K3 (viz níže). Dále po všech mohou následovat dva fonémy z pozic P2 a P3 (/mST/ pomst, /nKT/ adjunkt, /jSK/ vojsk, /rST/ verst, /lTS/ sulc). Výjimkou je /ň/, po němž stojí jen jeden konsonant, nepočítáme‑li cizí název Gdaňsk. Do pozice K1 také patří /P/, /T/, /K/, jestliže stojí bezprostředně po nukleárním fonému, aniž za ním další foném následuje (/P/: /xlaP/ chlap, /vrP/ vrb; /T/: /poT/ pod, /hlT/ hlt; /K/: /jaK/ jak, /smrK/ smrk), nebo jestliže za nimi následuje jeden konsonant (/PT/ skript, /Tř/ dovnitř, /KŠ/ jakžtakž) či konsonanty dva (/PST/ zábst, /TST/ péct, /KST/ text).
POSTNUKLEÁRNÍ POZICE K2. Okluzivy /P/, /T/, /K/ patří také do pozice K2, a to stojí‑li mezi dvěma konsonanty (/rPT/ excerpt, /nTŠ/ pomeranč, /nKT/ adjunkt). Dalšími členy pozice K2 jsou fonémy /ř/, /F/ a /X/, jež mají společné distribuční vlastnosti. Mohou se kombinovat s jiným konsonanty, ale pouze s jedním. Buď je předchází foném z pozice K1 (/Kř/ mokř, /rF/ harf, /rX/ arch), n. za nimi následuje foném z pozice K3 (/řT/ buřt, /FT/ pravd, /XŤ/ nechť). Před a za /ř/ jsou doloženy jen okluzivy, v substandardní č. též frikativa (/Fř/ v otevř). Do K2 též náleží frikativy /S/ a /Š/. Stejně jako před /F/ a /X/ může před nimi stát jeden foném z pozice K1 (/jS/ rorejs, /mŠ/ jímž) a za nimi foném z pozice K3 (/ST/ kost, /ŠŤ/ poušť). Od ostatních frikativ se však liší tím, že tyto dvě možnosti mohou nastat zároveň (/KST/ text, /mŠT/ kumšt).
POSTNUKLEÁRNÍ POZICE K3. V pozici K3 se objevují všechny čtyři okluzivy /P/, /T/, /K/ a /Ť/, avšak /Ť/ patří jen sem. Před ním může stát jeden foném z pozice K1, n. K2 (/rŤ/ žerď, /ŠŤ/ poušť). Jeho příslušnost do pozice K3 dovoluje, aby před ním stály dva periferní fonémy, avšak taková kombinace je doložena jen v archaickém ačť (tj. /TŠŤ/). Zbývající okluzivy /P/, /T/, /K/ do pozice K3 patří, stojí-li před nimi foném z pozice K2 (/SP/ výsp (gen.pl. od výspa), /XT/ ksicht, /FK/ tomahavk), n. předcházejí‑li je dva konsonanty (/TSP/ zácp (gen.pl. od zácpa), /rPT/ excerpt, /nKT/ adjunkt). Dva konsonanty mohou též předcházet frikativy /S/ a /Š/, jež do K3 rovněž patří (/nTS/ princ, /jTŠ/ půjč). V K3 se /S/ a /Š/ dále vyskytuje, pokud je před nimi foném /X/ z pozice K2. Pro /S/ je toto však doloženo jen v příjmení Fuchs; pro /Š/ pak v jejichž.
POSTNUKLEÁRNÍ ARCHIPOZICE EKVIVALENTNÍ POZICÍM K2 A K3. Sem patří fonémy /m/, /n/, /ň/, /r/ a /l/, pokud stojí po jiném a pouze jednom konsonantu. V tomto případě vždy stojí na konci fonotagmatu (např. /lm/ jilm, /jn/ hejn, /rň/ čerň, /jr/ chejr, /jl/ hejl).
1.1.4 Omezení souvýskytu fonémů
Fonotaktický popis je vždy nutné doplnit pravidly omezujícími společný výskyt fonémů v rámci jednoho fonotagmatu, poněvadž některé fonémy se vyznačují ↗defektivní distribucí. Distribuční jednotka prezentovaná v tab. 3 mnohá z těchto omezení ve své struktuře zahrnuje. Příkladem omezení, jež jsou v distribuční jednotce „zakódovány“, je fakt, že na začátku fonotagmatu před /v/ nemohou nikdy stát labiální okluzivy /p/ a /b/, byť ostatní okluzivy ano (srov. tvůj), n. fakt, že na konci fonotagmatu před /ř/ nemůže stát /Ť/, ale ostatní okluzivy ano (srov. pepř). Jiná omezení je nutné specifikovat samostatně.
Společný výskyt periferních fonémů (konsonantů) a nukleárních fonémů není v č. výrazně omezený. Omezená kombinovatelnost nukleárních semikonsonantů již byla zmíněna. Naopak před a za vokály může stát jakýkoliv konsonant. Výjimkou jsou dlouhé středové vokály /ē/ a /ō/, před nimiž nestojí palatální okluzivy /ť/ a /ď/. Obecně je v sousedství dlouhých vokálů (včetně diftongálních vokálů) doloženo méně konsonantických kombinací než v sousedství vokálů krátkých.
Výskyt fonémů na začátku fonotagmatu v č. neovlivňuje výskyt fonémů na konci fonotagmatu, ačkoliv jsou jaz., v nichž taková omezení existují (viz ✍Hervey, 1978). Jedinou již zmíněnou výjimkou je fakt, že fonotagma v č. může obsahovat maximálně šest konsonantů (tj. ne-nukleárních fonémů).
Největší omezení se týkají společného výskytu konsonantů. Např. kombinace tří okluziv n. tří nazál vedle sebe nejsou možné, ale kombinace tří a čtyř frikativ ano (/FSx/ vzchopit se, /FSxv/ v archaickém vzchvívati se). Kombinace dvou konsonantů stejného místa artikulace jsou možné (/Fp/ vpálit, /Sd/ zdar, /Šť/ štít) s výjimkou kombinací dvou velár, pokud nepočítáme předložková spojení jako k chalupě, k hospoděn. cizí slova jako khaki. Kombinace nazály plus okluzivy jsou na začátku fonotagmatu možné, ale jen pokud následuje sonanta n. nazála (/mdl/ mdlo, /mkn/ mknouti). Č. je známá tím, že dovoluje kombinace dvou okluziv (např. /Tb/ dbát, /Pt/ pták, /Kť/ Ktiš (název obce), /Tk/ tkát), avšak ne všechny jsou možné. Palatální okluzivy nestojí před jakýmkoliv konsonantem (včetně nukleárních semikonsonantů /r/ a /l/), před velárními okluzivami nestojí labiální okluziva, před palatálními okluzivami nestojí alveolární okluziva. Na konci fonotagmatu nemůže po jakékoliv okluzivě stát labiála n. velára (včetně frikativ). Jak již bylo řečeno, na začátku fonotagmatu mohou za alveolárními okluzivami stát dva konsonanty, ale druhý z nich nemůže být nazála, /ř/, /r/ nebo /l/. Pokud je nukleární semikonsonant jádrem fonotagmatu, fonotagma nemůže obsahovat /ř/ nebo /j/. Foném /ř/ se nevyskytuje v jedné kombinaci s palatálními frikativami /š/ a /ž/ mimo archaické žření („hryzání, kolika“). Další omezení podrobně rozebírá ✍Bičan (2013).
- Bell, A. Distributional Syllable. In Juilland, A. (ed.), Linguistic Studies Offered to Joseph Greenberg 2: Phonology, 1976, 249–262.
- Bell, A. Syllabic Consonants. In Greenberg, J. (ed.), Universals of Human Language 2: Phonology, 1978, 153–201.
- Bičan, A. Distributional Unit: Hypothesis and Testing. In Bičan, A. & P. Rastall (eds.), Axiomatic Functionalism: Theory and Application, 2011, 103–142.
- Bičan, A. Phonotactics of Czech, 2013.
- Bičan, A. On the Czech Nuclear /r/ and /l/. In Witkoś, J. & S. Jaworski (eds.), New Insights into Slavic Linguistics, 2014, 21–33.
- Bičan, A. Kvantitativní analýza slabiky v českém lexikonu. Linguistica Brunensia 63/2, 2015, 87–107.
- Blevins, J. Independent Nature of Phonotactic Constraints. In Féry, C. & R. van de Vijver (eds.), The Syllable in Optimality Theory, 2003.
- Dixon, R. The Languages of Australia, 1980.
- Fischer-Jørgensen, E. On the Definition of Phoneme Categories on a Distributional Basis. Acta Linguistica 7, 1952, 8–39.
- Fonologický korpus češtiny (http://ujc.cas.cz/phword).
- Frisch, S. & N. Large ad. Perception of Wordlikeness: Effects of Segment Probability and Length on the Processing of Nonwords. Journal of Memory and Language 42, 2000, 481–496.
- Fudge, E. Syllables. Journal of Linguistics 5, 1969, 253–286.
- Goldsmith, J. The Syllable. In Goldsmith, J. & J. Riggle ad. (eds), The Handbook of Phonological Theory, 2011, 164–196.
- Hattala, M. Počátečné skupeniny souhlásek československých, 1870.
- Haugen, E. The Syllable in Linguistic Description. In Halle, M. & H. G. Lunt ad. (eds.), For Roman Jakobson, 1956, 213–221.
- Hay, J. & J. Pierrehumbert ad. Speech Perception, Well-formedness and the Statistics of the Lexicon. In Local, J. & R. Ogden ad. (eds.), Phonetic Interpretation: Papers in Laboratory Phonology VI, 2003, 58–75.
- Hervey, S. On the Extrapolation of Phonological Forms. Lga 45, 1978, 37–63.
- Kučera, H. The Phonology of Czech, 1961.
- Kučera, H. & G. Monroe. A Comparative Quantitative Phonology of Russian, Czech, and German, 1968.
- Ludvíková, M. & J. Kraus. Kvantitativní vlastnosti soustavy českých fonémů. SaS 26, 1966, 334–344.
- Mathesius, V. La structure phonologique du lexique du tchèque modern. TCLP 1, 1929, 67–84.
- Mazlová, V. Jak se projevuje zvuková stránka češtiny v hláskových statistikách. NŘ 30, 1946, 101–111, 146–151.
- Mulder, J. Sets and Relations in Phonology, 1968.
- Mulder, J. & S. Hervey. Language as a System of Systems. In Mulder, J. & S. Hervey, The Strategy of Linguistics, 1980.
- Novotná, J. Kombinační schopnost českých konsonantických fonémů. Studia z filologii polskiej i słowiańskiej 12, 1972, 269–284.
- Pike, K. Phonemics: A Technique for Reducing Languages to Writing, 1947.
- Pulgram, E. Syllable, Word, Nexus, Cursus, 1970.
- Rastall, P. Empirical Phonology and Cartesian Tables, 1993.
- Sawicka, I. Struktura grup spółgłoskowych w językach słowiańskich, 1974.
- Selkirk, E. The Syllable. In van der Hulst, H. & N. Smith (eds.), The Structure of Phonological Representations 2, 1982, 337–383.
- Scholes, R. Phonotactic Grammaticality, 1966.
- Sigurd, B. Phonotactic Structures in Swedish, 1956.
- Sigurd, B. Phonotactic Aspect of the Linguistic Expression. In Malmberg, B. (ed.), Manual of Phonetics, 1968.
- Spang-Hansen, H. Probability and Structural Classification in Language Description, 1959.
- Těšitelová, M. a kol. Kvantitativní charakteristiky současné češtiny, 1985.
- Trnka, B. Pokus o vědeckou teorii a praktickou reformu těsnopisu, 1937.
- Trnka, B. On the Frequency and Distribution of Consonant Clusters in Czech. Prague Studies in Mathematical Linguistics 3, 1972, 9–14.
- Trubetzkoy, N. Grundzüge der Phonologie, 1939.
- Vachek, J. Poznámky k fonologii českého lexika. LF 67, 1940, 395–402.
- Vogt, H. Phoneme Classes and Phoneme Classification. Wd 10, 1954, 28–34.
- Zec, D. The Syllable. In de Lacy, P. (ed.), The Cambridge Handbook of Phonology, 2007, 161–194.
URL: https://www.czechency.org/slovnik/FONOTAKTIKA (poslední přístup: 20. 4. 2024)
Další pojmy:
fonologieCzechEncy – Nový encyklopedický slovník češtiny
Všechna práva vyhrazena © Masarykova univerzita, Brno 2012–2020
Provozuje Centrum zpracování přirozeného jazyka